PCA가 말하는 것: 데이터들을 정사영 시켜 차원을 낮춘다면,
어떤 벡터에 데이터들을 정사영 시켜야 원래의 데이터 구조를 제일 잘 유지할 수 있을까?
※ 본 article에서는 열벡터(column vector) convention을 따릅니다.
PCA는 종합점수를 ‘잘’ 계산하는 방법
100명의 학생들이 국어 시험과 영어 시험을 봤다고 생각해보자.
영어 시험이 조금 더 어려웠고 그 결과 중 일부는 대략적으로 다음과 같았다고 하자.
| 국어 점수 | 영어 점수 |
|---|---|
| 100 | 83 |
| 70 | 50 |
| 30 | 25 |
| 45 | 30 |
| $\vdots$ | $\vdots$ |
| 80 | 60 |
국어 성적을 $x$ 축에, 영어 성적을 $y$ 축에 놓고 데이터를 시각화하면 다음과 같다.
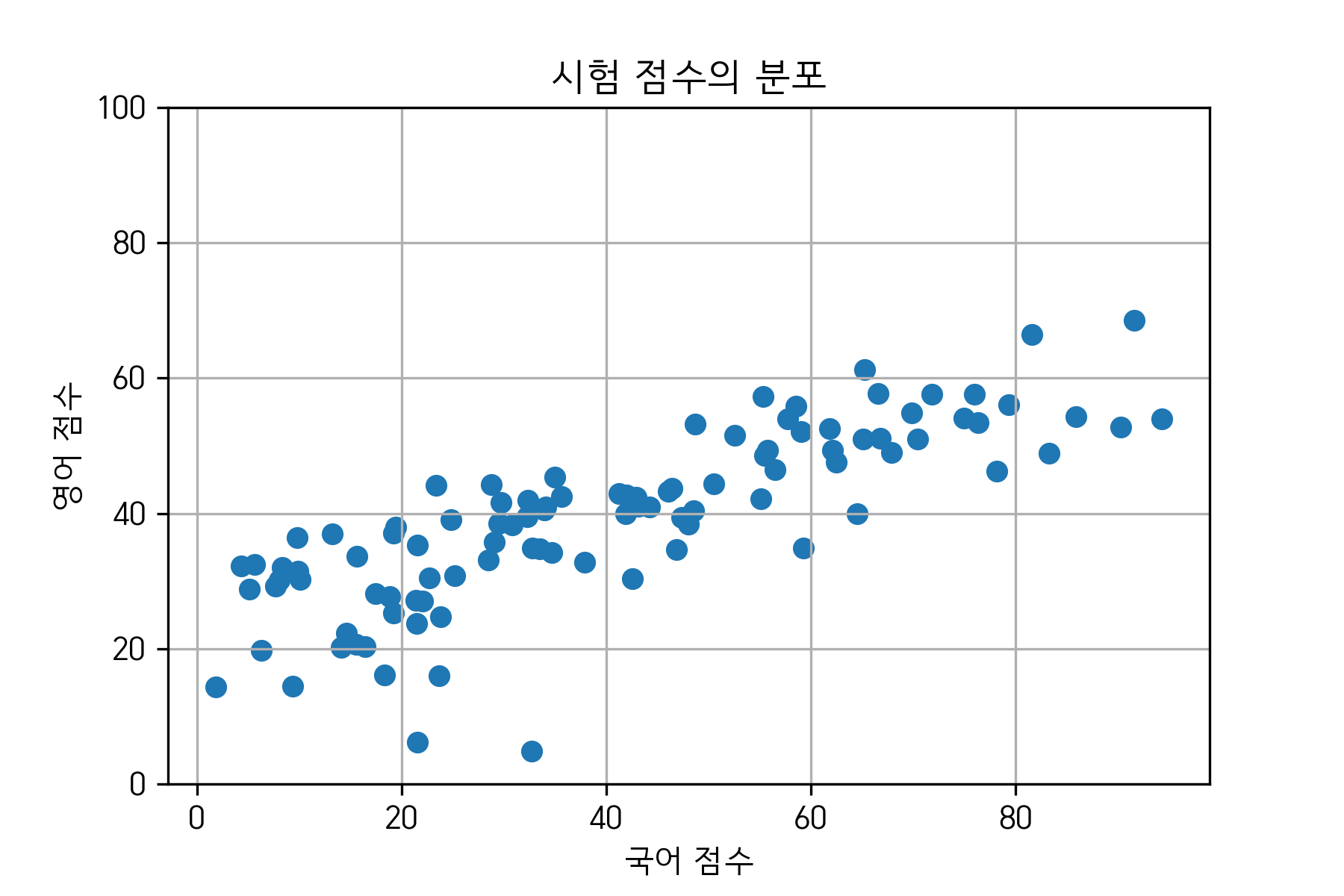
그림 1. 예시 데이터의 분포
만약 여기서 국어와 영어의 ‘종합 점수’를 만들고자 한다면 어떻게 하는 것이 좋을까?
가장 먼저 생각나는 방법은 두 점수의 평균을 취하는 것이다. 하지만, 또 다른 방법으로는 영어 시험이 상대적으로 더 어려웠으므로, 국어 대 영어 점수를 6:4로 비중을 두고 더할 수도 있다.
여기서, 평균을 취해 종합 점수를 낸다는 것과 6:4의 비중으로 종합 점수를 낸다는 것을 수학적으로 표현하면 어떻게 될까?
예를 들어, A라는 학생의 국어 성적, 영어 성적이 100점, 80점 이었다고 하자.
그렇다면, 5:5의 비율로 평균을 낸다는 것은
\[100 \times 0.5 + 80 \times 0.5\]라고 할 수 있으며, 6:4의 비율로 종합 점수를 낸다는 것은
\[100\times 0.6 + 80 \times 0.4\]라고 할 수 있다.
조금 더 용어를 써가면서 설명하자면, 식 (1)은 $(100, 80)$ 벡터를 $(0.5, 0.5)$벡터와 내적한 것이고, 식 (2)는 $(100, 80)$ 벡터를 $(0.6, 0.4)$ 벡터와 내적한 것이라고 할 수 있다.
그림으로 표현하면 다음과 같다.
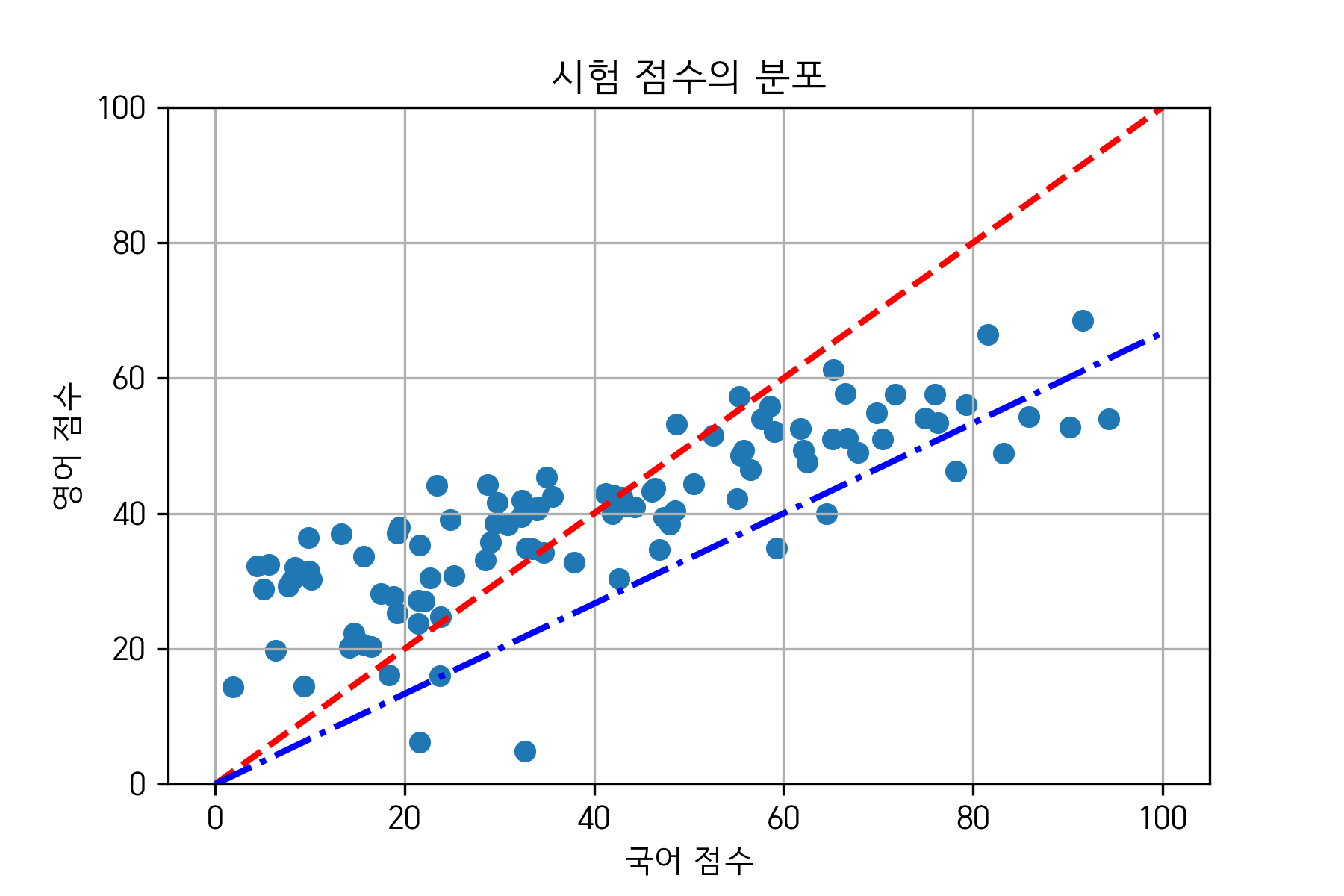
그림 2. 예시 데이터의 분포와 5:5 비율과 6:4 비율 선 (각각 빨강, 파랑)
즉, 종합 점수를 얻을 때, 5:5의 비율 혹은 6:4의 비율로 종합 점수를 얻는 방식은 수학적으로는 점수 벡터를 특정 비율을 표현하는 벡터에 내적(즉, 기하학적으로는 정사영) 하는 문제로 환원해 생각할 수 있다.
그렇다면 우리가 고민해야 할 핵심 문제는 이것이다.
- 데이터 벡터를 어떤 벡터에 내적(혹은 정사영)하는 것이 최적의 결과를 내주는가?
부차적으로 생각해볼 것은,
- 기왕 정사영 할 벡터(혹은 축)을 찾는데, 데이터 분포의 중심을 중심축(pivot)으로 움직이는 벡터를 찾는게 좋지 않을까?
이 문제에 대한 해결책은 ‘데이터의 구조(혹은 형태)’를 기술하는 수학적인 방법인 공분산 행렬로부터 찾을 수 있다.
공분산 행렬의 의미
공분산 행렬은 일종의 행렬로써, 데이터의 구조를 설명해주며, 특히 특징 쌍(feature pairs)들의 변동이 얼마나 닮았는가(다른 말로는 얼마만큼이나 함께 변하는가)를 행렬에 나타내고 있다.
공분산 행렬의 기하학적 의미
이번엔 공분산 행렬을 기하학적으로 파악해보도록 하자. 행렬이란 선형 변환이고 하나의 벡터 공간을 선형적으로 다른 벡터 공간으로 mapping 하는 기능을 가진다.
즉, 조금 다르게 말하면 우리는 지금의 데이터의 분포에 대해 “원래의 원의 형태로 주어졌던 데이터가 선형변환에 의해 변환된 결과로써 보자”라는 관점에서 데이터를 보고자 한다. 다음과 같이 어떤 행렬에 의해1 mapping 되는 mapping 전 단계의 데이터의 분포를 생각해보자.
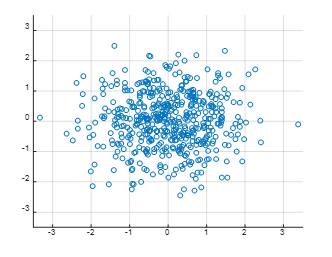
그림 3. 2차원 벡터공간에 bivariate Gaussian distribution을 통해 random values를 원형으로 뿌려보았음
그림 3과 같은 데이터에 대해 행렬을 적용하여 선형 변환을 시켜주면1 어떤 일이 일어나는지 알아보자. 그림 3에서 데이터가 자리잡고 있는 2차원 벡터공간에 대한 선형 변환은 그림 아래의 애플릿과 같이 나타난다.
각 버튼을 눌렀을 때 얻게 되는 결과들의 공분산 행렬은 아래와 같다.
4개의 행렬 중, Matrix 1에 대해서만 설명하자면, Matrix 1에서 보여주는 것은 다음과 같다.
Matrix 1의 1행 1열의 원소는 1번 feature의 variance를 나타낸다. 즉, x축 방향으로 얼마만큼 퍼지게 할 것인가를 말해준다.
1행 2열의 원소와 2행 1열의 원소는 각각 x, y축으로 함께 얼마만큼 퍼지게 할 것인가를 말해준다.
2행 2열의 원소는 y축 방향으로 얼마만큼 퍼지게 할 것인가를 말해준다.
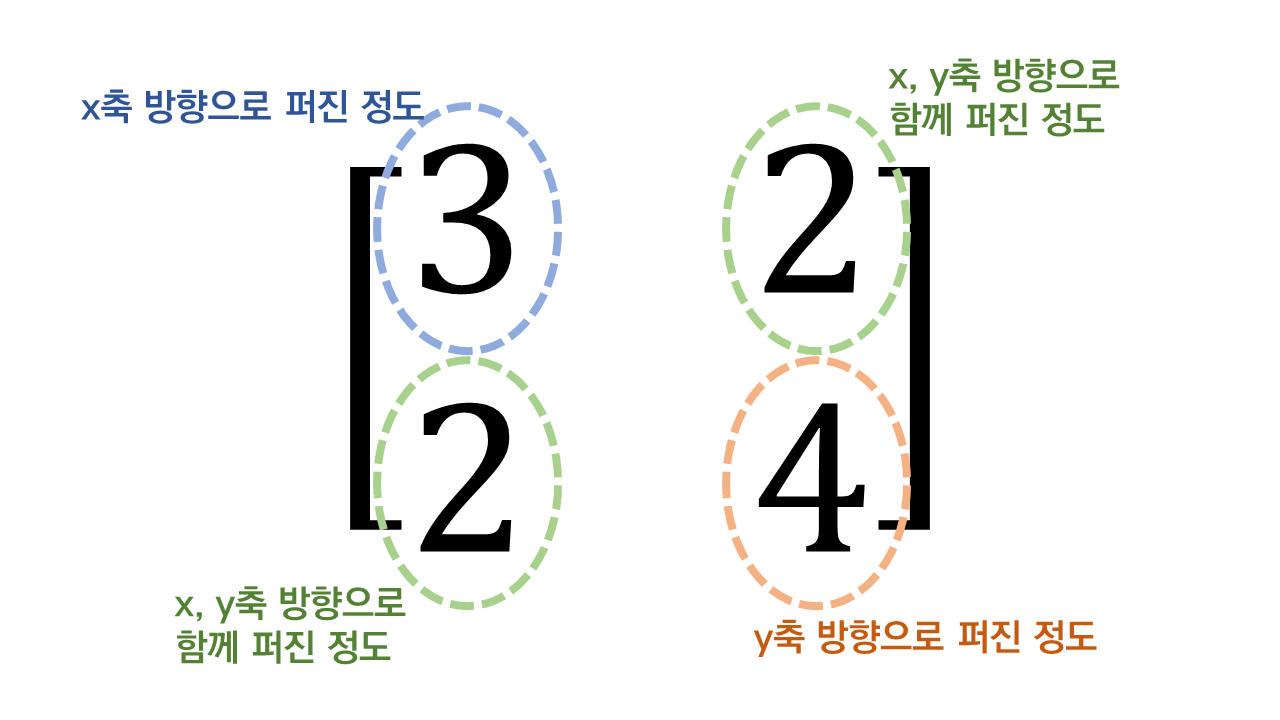
그림 4. 공분산행렬 Matrix 1의 각 원소들이 의미하는 것
고유 벡터(eigenvector)의 의미를 잘 생각해보면, 고유 벡터는 그 행렬이 벡터에 작용하는 주축(principal axis)의 방향을 나타내므로 공분산 행렬의 고유 벡터는 데이터가 어떤 방향으로 분산되어 있는지를 나타내준다고 할 수 있다.
고유 값은 고유벡터 방향으로 얼마만큼의 크기로 벡터공간이 늘려지는 지를 얘기한다2. 따라서 고유 값이 큰 순서대로 고유 벡터를 정렬하면 결과적으로 중요한 순서대로 주성분을 구하는 것이 된다. 아래의 그림 5에서 고유 벡터 두 개를 볼 수 있고 각각의 벡터의 크기가 각 벡터의 고윳값을 의미한다.
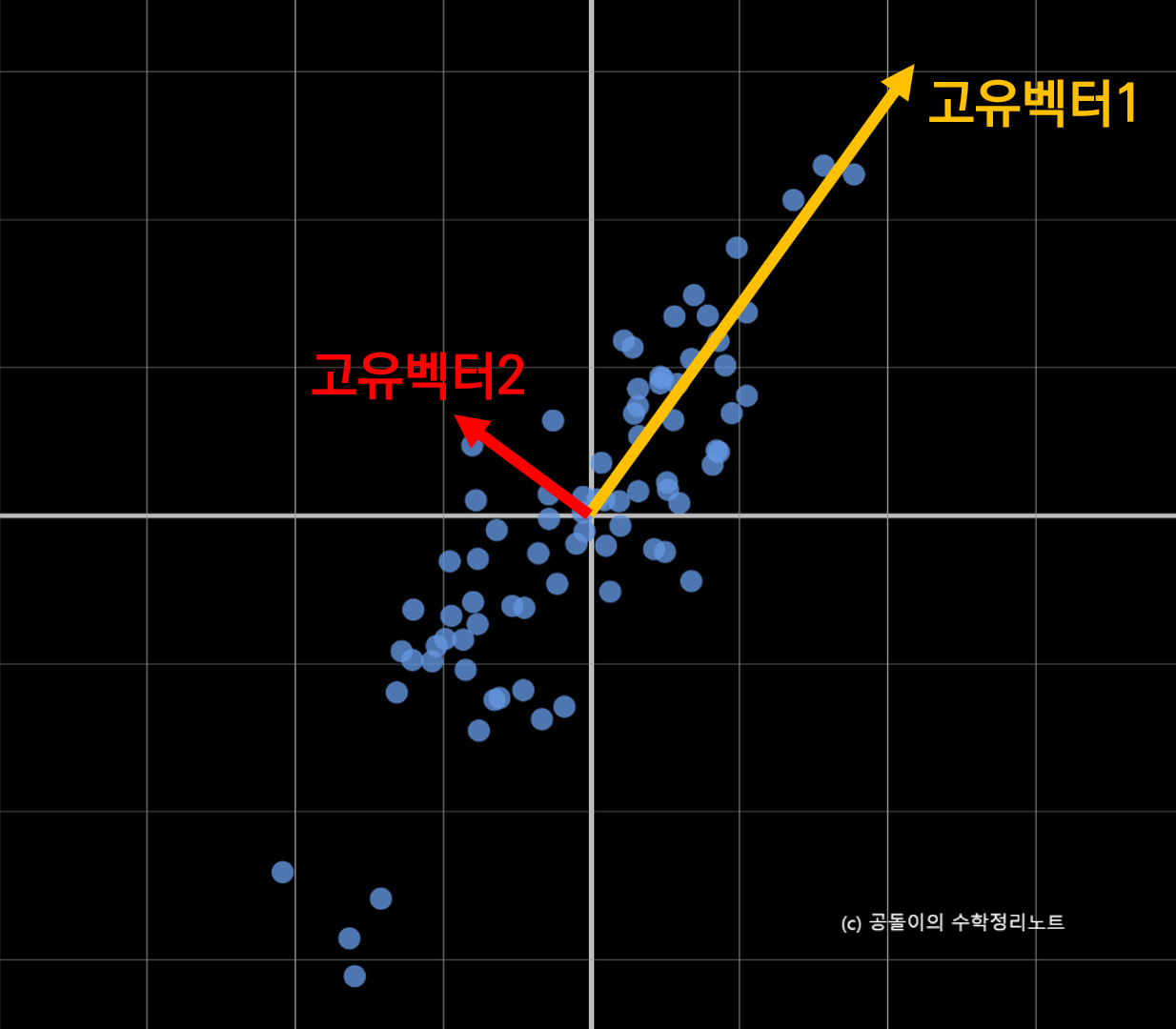
그림 5. 공분산행렬 Matrix 1의 고유벡터
즉, 우리가 고민했던 문제는 무엇인가? 바로 ‘데이터 벡터를 어떤 벡터에 내적(혹은 정사영)하는 것이 최적의 결과를 내주는가?’ 이다. 이 문제에 대한 해결은 바로 공분산 행렬의 고윳값과 고유 벡터를 구함으로써 가능하다.
공분산 행렬의 수식적 의미
공분산 행렬에 대해 수식적으로 이해해보자. 공분산 행렬은 2변량 이상의 변량이 있는 경우에 여러 개의 두 변량 값들 간의 공분산을 행렬로 표현한 것으로 정의하고 있다. 가령 $n$명의 사람들로부터 각각 $d$개의 특징(feature)을 추출했다고 하자. 그리고 이 데이터를 아래의 그림과 같이 행렬 $X$로 표현해보자.
이 때, 아래의 행렬의 각 열(feature)들의 평균 값은 $0$이라고 하자. 이러한 가정은 위에서 설명한 ‘부차적인 문제’인 데이터 분포의 중심을 중심축(pivot)으로 움직이는 벡터를 찾는데 도움을 줄 것이다3.
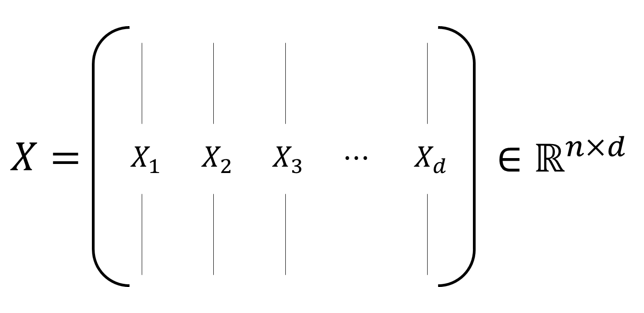
그림 6. d개의 n차원 열벡터를 쌓아서 얻은 데이터 행렬 X
행렬 $X$를 만드는 예를 생각해보자. 가령 5명의 사람으로부터 키와 몸무게를 다음과 같이 행렬 D에 넣어보자.
\[D = \begin{bmatrix} 170 & 70 \\ 150 & 45 \\ 160 & 55 \\ 180 & 60 \\ 170 & 80 \end{bmatrix}\]그러면 행렬 $X$는 행렬 $D$에서 각 열의 평균을 빼줌으로써 구할 수 있다.
\[X = D - mean(D) = \begin{bmatrix} 170 & 70 \\ 150 & 45 \\ 160 & 55 \\ 180 & 60 \\ 172 & 80 \end{bmatrix} - \begin{bmatrix} 166 & 62 \\ 166 & 62 \\ 166 & 62 \\ 166 & 62 \\ 166 & 62 \end{bmatrix} = \begin{bmatrix} 4 & 8 \\ -16 & -17 \\ -6 & -7 \\ 14 & -2 \\ 6 & 18 \end{bmatrix}\]이번에는 데이터 행렬 $X$를 이용해서 공분산 행렬을 얻어보고자 한다.
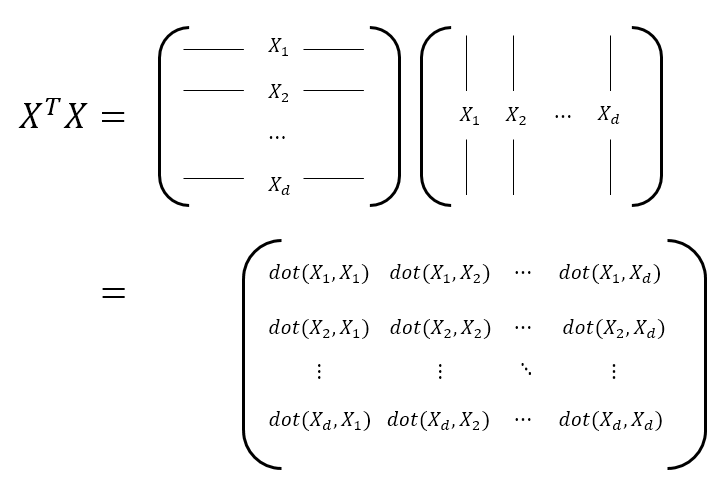
그림 7. 공분산 행렬을 계산하기 위해 각 데이터 특징들의 변동이 서로 얼마나 닮았는지 계산하는 과정.
여기서 dot($\bullet$,$\bullet$)은 두 벡터의 내적 연산을 의미한다.
이제, 그림 7에서 확인할 수 있는 $X^TX$의 의미는 무엇인가?
그림 7의 마지막 항(term)을 보면 $X^TX$의 $i$행 $j$열의 성분인 $(X^TX)_{ij}$는 $d$개의 feature 중 $i$번째 feature와 $j$번째 feature가 얼마나 닮았는지를 모든 사람으로부터 값을 얻어서 내적 연산을 취함으로써 확인시켜준다.
위에서 계속하던 예시에서 $X^TX$를 계산해보자.
\[X^TX = \begin{bmatrix} 4 & -16 & -6 & 14 & 6 \\ 8 & -17 & -7 & -2 & 18 \end{bmatrix} \begin{bmatrix} 4 & 8 \\ -16 & -17 \\ -6 & -7 \\ 14 & -2 \\ 6 & 18 \end{bmatrix} = \begin{bmatrix} 540 &426 \\ 426 & 730 \end{bmatrix}\]그런데 $X^TX$ 행렬이 가지는 문제는 숫자 $n$이 커질수록 내적 값은 계속 커진다는 것이다. 즉, 샘플을 모으면 모을 수록 결과값이 더 커진다는 의미이다. 따라서 이를 방지하기 위해서는 내적값들을 $n$으로 나눠주어 그 문제를 피할 수 있을 것이다. 그러면 다음과 같은 행렬을 생각할 수 있게 된다.
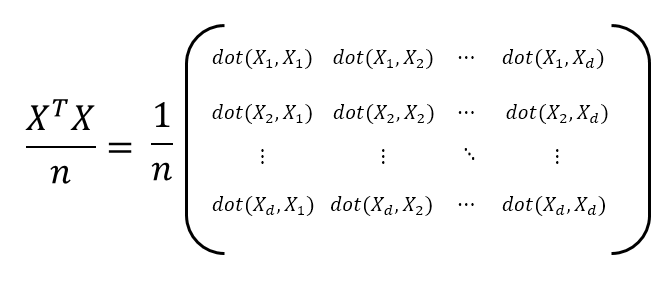
그림 8. 공분산 행렬의 계산. 데이터의 샘플 수 만큼 그 크기를 나눠주는 과정.
그림 8에 표현되어 있는 행렬을 공분산 행렬이라고 부른다. 즉, 데이터 행렬 $X$에 대해서 공분산행렬 $\Sigma$는
\[\Sigma = \frac{1}{n}X^TX\]이다4.
위에서 계속 진행하던 예시 데이터에서 공분산 행렬을 계산해보면 다음과 같다.
\[\Sigma = \frac{1}{5}X^TX = \frac{1}{5} \begin{bmatrix} 540 &426 \\ 426 & 730 \end{bmatrix} = \begin{bmatrix} 108 & 85.2 \\ 85.2 & 146 \end{bmatrix}\]공분산 행렬의 고유벡터와 최대 variance
혹시나 앞서 설명한 고유 벡터와 고유 값을 이용한 기하학적인 설명이 어려웠다면 이 파트에서 설명할 수식적인 설명이 더 도움이 될지도 모르겠다. 이 파트에서는 왜 고유벡터5에 데이터를 정사영하여 얻은 data의 variance가 최대가 되는지에 대해 설명하고자 한다.
예를 들어 $d$차원의 데이터를 정사영을 통해 1차원으로 차원 감소한다고 해보자. 이 때 정사영 대상인 임의의 단위 벡터 $\vec{e}$를 생각해보자. $\vec{e}$는 $d\times 1$차원의 벡터이다. 그러면 데이터 행렬 $X\in \mathbb{R}^{n\times d}$을 단위벡터 $\vec{e}$에 정사영 해주면 $(X\vec{e})\vec{e}$이므로 그 크기는 다음과 같이 쓸 수 있다.
\[X\vec{e} \in \mathbb{R}^{n\times 1}\]따라서 $\vec{e}$에 정사영 된 데이터의 variance는 다음과 같다.
\[Var(X\vec{e}) = \frac{1}{n}\sum_{i=1}^{n}\left(X\vec{e} - E(X\vec{e})\right)^2\]이 때, $X$의 각 열의 평균은 0이라고 가정한다면,
\[식(9) = \frac{1}{n}\sum_{i=1}^{n}\left(X\vec{e} - E(X)\vec{e}\right)^2 =\frac{1}{n}\sum_{i=1}^{n}\left(X\vec{e}\right)^2\]이다.
그러므로
\[Var(X\vec{e}) = \frac{1}{n}\left(X\vec{e}\right)^T\left(X\vec{e}\right)\] \[= \frac{1}{n}\vec{e}^TX^TX\vec{e} = \frac{1}{n}\vec{e}^T(X^TX)\vec{e}\] \[=\vec{e}^T\left(\frac{X^TX}{n}\right)\vec{e}\] \[=\vec{e}^T\Sigma\vec{e}\]와 같은 결과를 얻을 수 있다.
여기서 $\vec{e}$는 임의의 단위 벡터였는데 정사영한 데이터의 변위가 최대가 되려면 $\vec{e}$를 어떻게 고르면 좋을지 알아보자.
라그랑주 승수법을 이용하도록 하자. 이 때 목표함수는
\[\vec{e}^T\Sigma\vec{e}\]이며 제약조건은
\[\left|\vec{e}\right|^2=1\]이다.
따라서 다음의 보조방정식을 만들 수 있다.
\[L = \vec{e}^T\Sigma\vec{e} - \lambda(\left|\vec{e}\right|^2-1)\]보조방정식 $L$을 $\vec{e}$에 대해 편미분하면
\[\frac{\partial L}{\partial \vec{e}} = 2\Sigma\vec{e}-2\lambda\vec{e} = 0\]이므로
\[\Sigma\vec{e} = \lambda\vec{e}\]의 조건을 만족하는 $\vec{e}$가 선택되면 목표함수 $\vec{e}^T\Sigma\vec{e}$가 최대가 될 수 있다는 것을 알 수 있다.
또, 라그랑주 승수법에 의해 나온 결과를 통해
\[Var(X\vec{e}) = \vec{e}^T\Sigma\vec{e} = \vec{e}^T\lambda\vec{e} = \lambda\vec{e}^T\vec{e} = \lambda\]라는 사실을 알 수 있다. 따라서 eigenvector 를 통해 정사영 했을 때 variance는 eigenvalue임을 알 수 있다.
How many dimensions?
다차원의 데이터에서 차원 감소를 시켜주는 것이 PCA의 주목적인 것은 알겠지만, 그렇다면 고차원의 데이터를 어디까지 차원감소 시켜주는 것이 타당할까?
가령 $d$차원의 데이터를 $m$차원까지 감소시켜준다고 해보자 (여기서 $m<d$). $d$ 차원의 데이터이므로 총 $d$개의 eigenvalue를 계산 할 수 있다. (물론 데이터의 공분산 행렬이 full rank임을 가정했을 때이다.)
이것을 $\lambda_1, \lambda_2, \cdots, \lambda_d$로 표현해주자 (여기서 $\lambda_1 \geq \lambda_2 \geq \cdots, \geq \lambda_d$)
이 때, 논리적인 방법 중 하나는 전체 데이터의 variance 중 가령 90%만큼을 설명하는 차원까지 감소시켜주는 것이다. 즉,
\[\frac{\sum_{j=1}^{m}\lambda_j}{\sum_{i=1}^{d}\lambda_i} = 0.9\]인 적절한 $m$을 찾아 그 차원까지 감소시켜주는 것이다.
또 다른 방법으로는 scree plot을 이용하는 방법이 있다. 이 방법은 다소 주관적일 수 있는데 2차원 plot을 그리는데 x 축에는 dimensions, y 축에는 해당 dimension의 eigenvalue를 기재한다. 예를 들어 다음과 같은 그림일 수 있다.
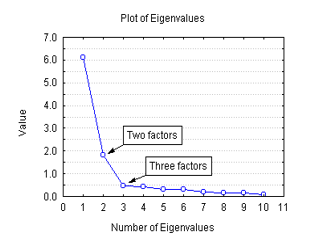
그림 9 scree plot의 예시
여기서 보면 세 번째 eigenvalue부터 갑자기 꺾이는 현상이 보인다.
그러면 이때는 3차원까지 차원 감소를 시켜준다는 식으로 결정하는 것이 scree plot을 이용한 방법이다. scree plot은 PCA외에도 많은 method에서 사용된다.
-
실제로 곱해지는 행렬은 공분산 행렬이 아닌 공분산 행렬을 숄레스키 분해하여 얻은 삼각행렬이다. 이에 관한 더 깊은 논의는 마할라노비스 거리 편에서 확인할 수 있다. ↩ ↩2
-
정확히는 해당 벡터에 정사영했을 때 분산값과 같다. ↩
-
만약 각 열들의 평균 값이 0이 아니라고 하면, 각 열들의 평균값을 빼줌으로써 각 열들의 평균값이 0인 행렬을 구할 수 있을 것이다. ↩
-
조금 더 엄밀하게는 n대신 n-1로 나누어주어야 sample의 covariance를 얻을 수 있다. n이 꽤 큰 숫자라면 크게 결과가 달라지지는 않겠지만… ↩
-
혹은 고유 벡터들이 이루는 열벡터 공간 ↩