※ 이 포스팅은 미술관에 GAN 딥러닝 실전 프로젝트의 결과와 소스 코드를 이용해 작성한 것임을 밝힙니다.
※ 이 포스팅의 소스 코드는 박해선 님의 깃허브 레포에서 확인하실 수 있습니다.
Prerequisites
해당 포스팅을 이해하기 위해선 다음의 내용에 대해 알고 오시는 것을 추천드립니다.
오토 인코더 짧게 복습
Variational AutoEncoder(VAE)는 기본적으로 AutoEncoder(AE)의 형태를 그대로 유지하고 있다.
따라서, VAE를 잘 이해하기 위해선 AE의 특성을 잘 파악하고, 어떤 부분에서 AE의 한계점이 있으며, 그 한계점들을 극복하기 위해 VAE는 어떤 보완책들을 내놓았는지 알아볼 필요가 있다.
AutoEncoder편의 내용을 짧게 복습해보자.
기본적으로 AE는 데이터를 압축하고 압축 해제하는 과정을 거치게 만든 뉴럴네트워크이다.
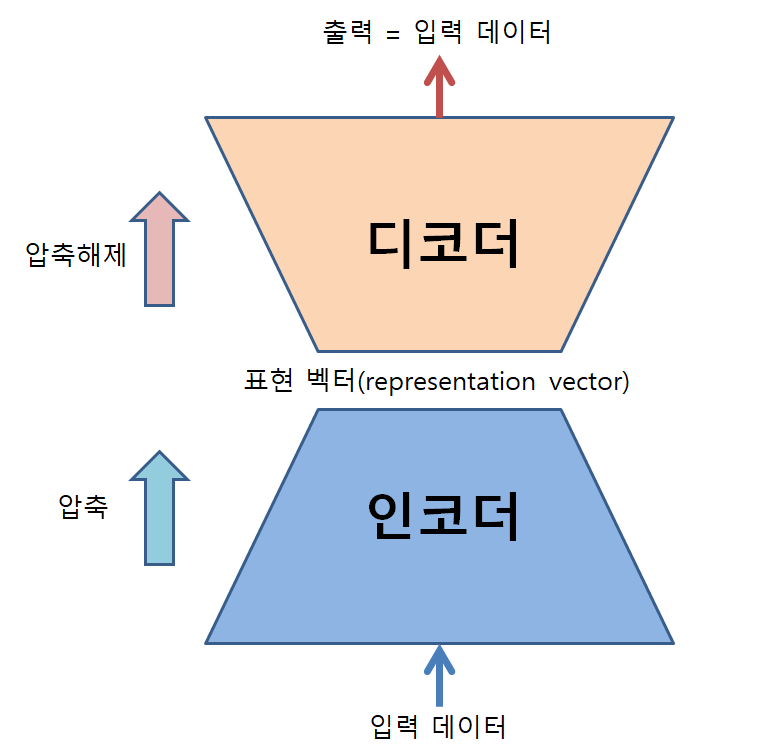
그림 1. 오토인코더의 구조와 역할
이런 일을 수행할 수 있도록 오토인코더를 학습할 때는 인코더 부(部)의 입력과 디코더 부(部)의 출력은 모두 동일한 입력데이터가 될 수 있도록 한다.
굳이 왜 입력데이터를 넣고 똑같은 출력데이터를 얻는가 하면, 입력 데이터를 표방할 수 있는 조금 더 낮은 차원의 데이터(표현 벡터)를 비선형적으로 얻을 수 있기 때문이다.
이 때, 데이터를 압축해 얻어낸 새로운 종류의 벡터를 ‘표현 벡터(representation vector)’ 혹은 latent factor라고 부른다.
가령, 28*28 = 784 차원인 MNIST 데이터셋을 이용해 2차원 표현 벡터를 얻게 된다고 하면 다음과 같이 2차원 평면 상에 label을 붙여 표현해 볼 수 있다.
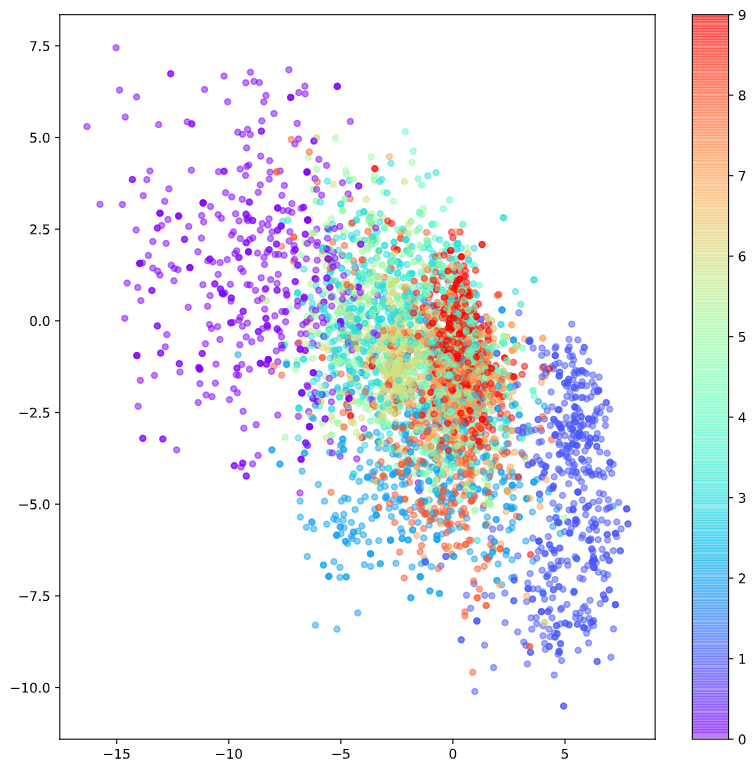
그림 2. MNIST 데이터의 representation vector의 시각화
여기까지의 “압축” 과정을 통해 고차원 데이터를 저차원으로 변환시켜주는 과정을 “인코딩”이라고 하고, 이러한 일을 수행하는 뉴럴네트워크 부(部)를 “인코더”라고 부른다.
뿐만 아니라 AE는 “압축해제”를 수행할 수도 있는데, 그림 2에 있는 표현 벡터 공간(혹은 latent space)에서 임의로 좌표를 선정해 해당 좌표의 데이터를 디코딩함으로써 전혀 보지 못했던 새로운 샘플을 생성할 수도 있다.
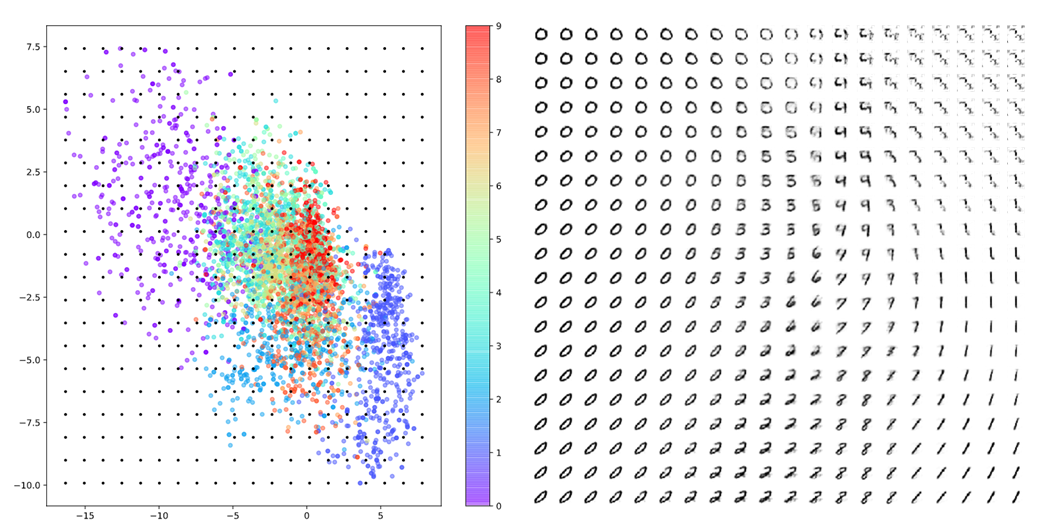
그림 3. 표현 벡터 공간(혹은 latent space) 상에서 랜덤 샘플링을 통해 얻은 표현 벡터를 디코딩한 결과
오토인코더의 한계점과 보완 방법
그렇다면, “압축”과 “압축 해제”의 기능이 의도한 것 처럼 구현되어 보이는 오토인코더(AutoEncoder, AE)는 어떤 부분에서 성능을 개선시킬 수 있을까?
첫 번째로는 오토인코더는 지금껏 보지 못했던 데이터들을 생성할 때의 퀄리티가 떨어진다. 즉, AE의 latent space에서 빈 공간에서부터 생성된 데이터들은 품질이 떨어진다. 어떻게 생각하면 AE의 디코더의 디코딩 기능이 인코더가 특정 데이터를 인코딩 해 놓은 좌표에만 잘 작동하게끔 오버피팅(overfitting)되어 있는 상태라고도 말할 수 있을 것이다.
두 번째 한계점은 표현 벡터의 벡터 공간 상의 벡터들이 (0, 0)에 대칭이거나 값이 제한되어 있지 않다. 예를 들어 그림 2의 표현 벡터들의 분포를 보면 y축 상에서 양수 영역보다 음수 영역에 더 많은 포인트들이 분포하고 있다. 다시 말해 인코딩 시 표현 벡터들의 위치를 선택하는 특정한 규칙이 없다보니, 디코딩 시에는 항상 인코더가 표현 벡터 벡터 공간의 어떤 좌표에 해당 데이터를 옮겨 담았는지 매번 확인해서 sampling을 해야하는 번거로움이 있는 것이다.
또, 세 번째 한계점은 어떤 숫자들은 매우 작은 영역에 밀집되어 있는데, 또 어떤 숫자들은 넓은 지역에 퍼져 있다는 점이다. 가령, 그림 2를 보면 숫자 0은 좌측 상단에 넓게 퍼져있는 것에 반해 숫자 9는 중앙에 빨간색으로 아주 작게 밀집되어 있는 것을 알 수 있다.
그렇다면, 이러한 한계점 세 가지를 어떻게 해결하는 것이 좋을까?
첫 번째 한계점에 대한 보완책
첫 번째 한계점에 대해서는 인코더가 데이터를 “압축”할 때 원래 인코더가 위치시키려고 했던 표현 벡터 벡터 공간 상의 정확한 그 위치가 아닌 그 위치에서 살짝 벗어난 곳에 점을 찍어줄 수 있도록 인코더를 수정해야 한다. randomness를 주는 방법은 여러가지가 있을 수 있지만 일반적으로 많이 사용되는 방법 중 하나는 Gaussian 분포를 이용하는 것이다.
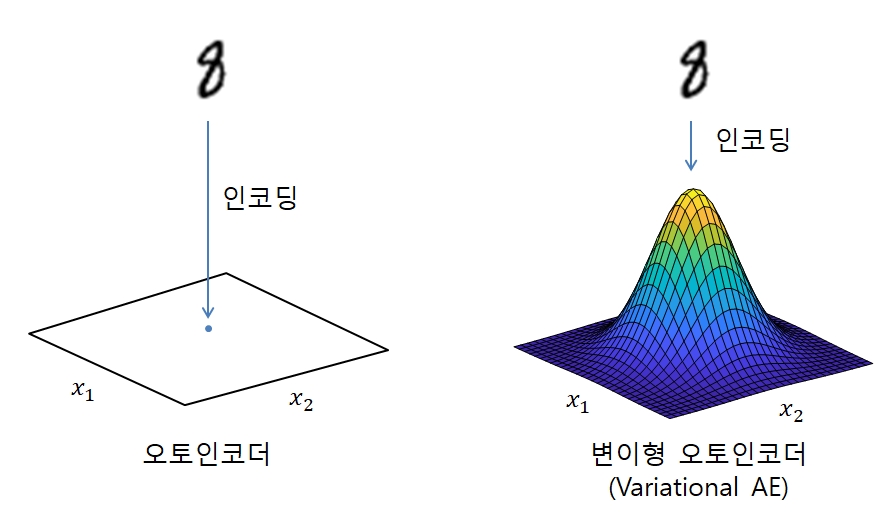
그림 4. 인코더가 표현 벡터 공간에 데이터를 인코딩 할 때 randomness를 추가해주면 디코더의 overfitting 현상을 막을 수 있다.
여기서 하나 궁금한 점이 생길 수 있다. 가령, 그림 4에서와 같이 ‘8’이라는 형태의 입력 데이터가 들어왔다고 했을 때 VAE에서 찍어줄 인코딩 좌표(즉, sampling 할 Gaussian 분포의 평균값)와 해당 Gaussian 분포의 분산 값은 어떻게 계산할 것인가라는 문제이다.
VAE에서는 방금 언급한 평균과 분산 값을 모두 각각의 Fully Connected 뉴럴넷에서 계산하여 출력한 값으로 계산하여 사용한다. 물론 여기서 평균값과 분산값의 계산을 맡게 될 Fully Connected 뉴럴넷은 본인이 계산하고 있는 값이 평균과 분산이라는 사실은 모른채 VAE의 학습 과정에 들어가게 될 것이다.
여기서 randomness를 추가해주기 위해
이라는 좌표에 표현 벡터가 찍히게 된다.
(여기서 “계산된 평균값” 혹은 “계산된 표준편차”는 꼭 스칼라 값일 필요는 없다. 만약 표현 벡터의 벡터공간을 2차원 벡터공간으로 생각한다면 “계산된” 평균값/표준편차는 2차원 벡터로 생각하면 된다.)
학습 과정에서 비슷한 데이터들(즉, 결론적으로는 label이 같은)은 “계산된 평균값”이 유사해 질 것이고, 이 과정에서 “계산된 표준편차” 역시도 모든 데이터에 대해서 작아질 것이므로 (뉴럴넷도 게속 학습시켜주면 점점 지금 보고 있는 데이터들이 지금껏 봤던 데이터들 중 어떤 것과 닮았는지 확신을 더 갖게 된다.) 결국 각 label들의 분포는 정규분포의 형태로 클러스터링 되게 된다.
두 번째 한계점에 대한 보완책
두 번째 한계점에 대해서는 인코더가 임베딩 시키는 표현벡터 벡터공간의 형태에 대한 제약조건을 걸어주어야 한다.
다양한 형태의 후보군이 있으나 우리는 평균이 0이고 표준편차가 1인 표준정규분포의 형태로 제약하도록 하자.
특별히 그래야만 하는 이유가 없으나, 추후 데이터 reconstruction(즉 디코딩)을 수행할 때 선정할 표현 벡터 벡터 공간의 임의의 좌표를 쉽게 sampling하기 위함이다.
다시 말해, 표준 정규분포의 sampling은 컴퓨터로 쉽게 쓸 수 있게 구현되어 있기 때문이다.
우리는 분포 형태의 제약의 방법으로 KL divergence를 사용하도록 하자.
KL divergence는 쉽게 말해 한 확률 분포가 다른 분포와 얼마나 다른지를 측정하는 도구이다.
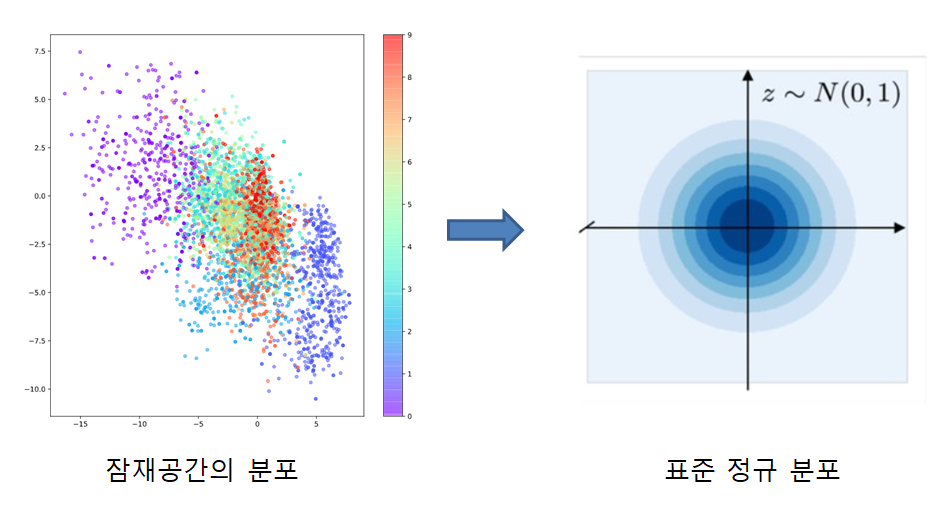
그림 5. KL divergence를 이용해 표현벡터 벡터공간 상의 임베딩 형태를 표준정규분포에 제약하자
세 번째 한계점에 대한 보완책
세 번째 한계점은 첫 번째와 두 번째 보완책을 통해서 이미 보완되었다고 할 수 있다.
각각의 label들은 클러스터를 이루면서도 동시에 전체적인 임베딩 분포도 표준정규분포를 따라야 하는데,
이 과정에서 각각의 label에 해당되는 클러스터들은 최대한 오밀조밀하게 효율적으로 비슷한 variance를 갖고 분포할 수 있도록 인코더가 학습될 것이기 때문이다.
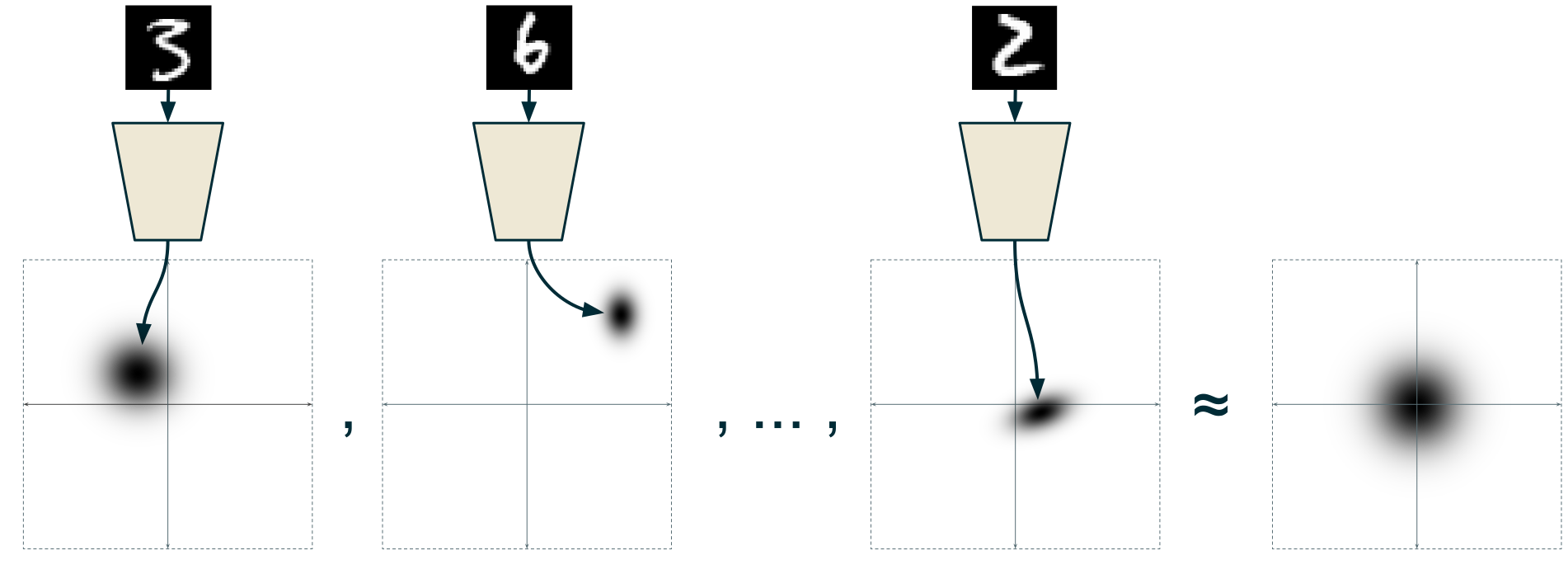
그림 6. 각 label별 클러스터와 전체적인 분포의 형태가 고정되었을 때 세 번째 한계점이 자연스레 해결된다.
그림 출처: [Isaac Dykeman의 블로그](https://ijdykeman.github.io/ml/2016/12/21/cvae.html)
VAE를 이용하여 획득한 표현 벡터 결과
아래의 그림 7을 보면 VAE를 이용해 획득한 표현 벡터의 벡터 공간 상의 임베딩을 볼 수 있다.
그림 7을 그림 2와 비교해보면 확실히 (0,0)을 중심으로 하여 정규분포의 형태에 가깝게 퍼져있고, 각 label 별로도 퍼진 정도가 AE에 비해 균일한 것을 확인할 수 있다.
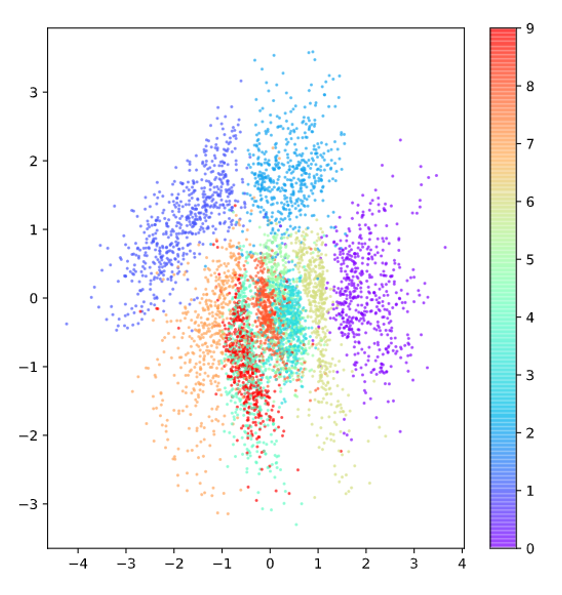
그림 7. VAE를 이용해 획득한 표현벡터 벡터 공간상의 임베딩
또, 그림 8에서 보여주고 있는 표현벡터 벡터공간을 임의로 sampling 하여 얻은 reconstruction data역시 마찬가지로 그림 3에서 얻은 데이터들에 비해 좀 더 연속적이고 다양한 숫자들에 대해 획득되고 있는 것을 볼 수 있다.
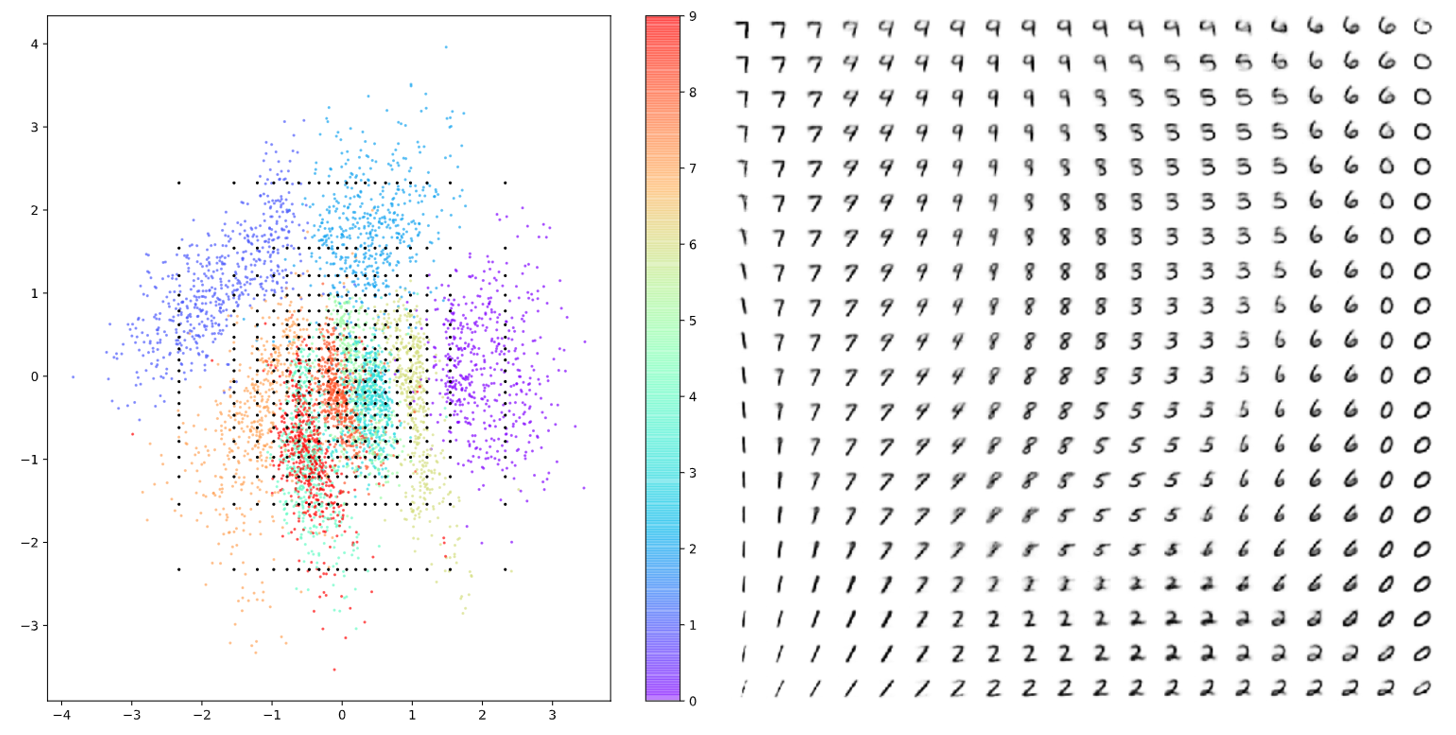
그림 8. 표현벡터 벡터 공간에서 임의로 sampling 하여 얻은 reconstructed data