확률 분포로부터 샘플 추출
uniform distribution이나 정규분포의 샘플은 컴퓨터를 이용하면 코드 한 줄이면 추출할 수 있다.
MATLAB의 경우는 아래와 같은 코드를 이용할 수 있다.
uniform_sample = rand(1,1)
normal_sample = randn(1,1)
그런데, 임의의 수식을 가진 확률밀도함수로부터 랜덤한 샘플을 추출하려면 어떻게 해야할까?
Rejection Sampling
대략적인 수식을 알고 있는 어떤 확률밀도함수가 있다고 하자.
가령 아래와 같은 함수 $f(x)$를 생각해볼 수 있다.
\[f(x) = 0.3\exp\left(-0.2x^2\right) + 0.7\exp\left(-0.2(x-10)^2\right)\]이 함수 $f(x)$는 정확히 말하면 확률밀도함수라고는 할 수 없다. 왜냐하면 $-\infty$부터 $\infty$까지 이 함수를 적분했을 때의 전체 면적이 1이 아니기 때문이다. (정확히는 $\sqrt{5\pi}$이다.)
하지만, 이와 같이 정확한 확률밀도 함수를 알기 곤란할 때나 확률밀도 함수의 수식은 있지만 해당 함수로부터 sample을 추출하기 어려운 경우 sampling 방법이 필요할 수 있다.
우리가 샘플을 추출하고자 하는 이 유사 확률 분포를 ‘타겟 분포(target distribution)’라고 이름 붙이고, $f(x)$로 쓰도록 하자.
이 타겟 분포를 plot 해보면 다음과 같은 형태를 가지고 있다는 것을 알 수 있다.
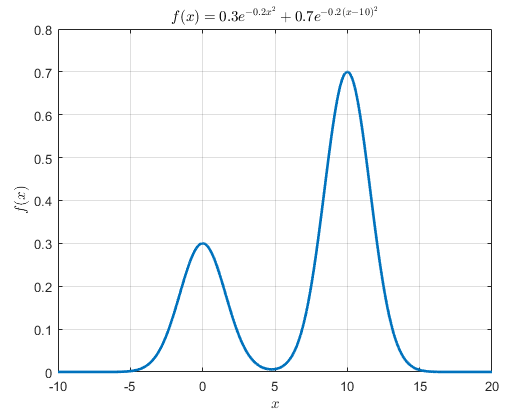
그림 1. 수식을 알고 있는 임의의 유사-확률밀도 함수
만약에 우리가 이런 형태의 유사 확률밀도함수로부터 샘플을 추출하려고 하면 어떻게 샘플을 추출할 수 있을까?
이럴 때 사용할 수 있는 것이 rejection sampling이라고 할 수 있다.
제안 분포(혹은 유사 분포)
rejection sampling의 첫 단계는 제안 분포(proposal distribution)를 설정하는 것이다.
앞으로 제안 분포를 $g(x)$로 쓰도록 하자.
제안 분포 $g(x)$는 우리가 쉽게 샘플을 추출할 수 있는 분포를 이용해서 생성할 수 있다.
가령, uniform distribution이 생긴게 가장 단순하기 때문에 uniform distribution을 이용해서 제안 분포를 만들 수 있을 것이다.
교과서에서는 타겟 분포와 가장 유사한 형태의 제안 분포를 설정하는 것이 좋다고 되어 있다.
(하지만, uniform distribution을 쓰는게 제일 속편하다.)
이렇게 제안 분포를 일단 결정했으면 타겟 분포와 제안 분포를 일단 그려보자.
이 예시에서는 제안 분포로 결정한 uniform distribution의 정의역의 범위를 아래와 같이 설정하였다.
그 이유는 $x$ 범위에서 가능한 타겟 분포를 모두 포함할 수 있도록 하기 위해서이다.
\[x = \lbrace x|-7\leq x \lt 17\rbrace\]그러면, 우리의 제안분포는 다음과 같다.
\[g(x) = \begin{cases} 1/24 & \text{if} -7 \leq x \lt 17 \\ 0 & \text{otherwise} \end{cases}\]
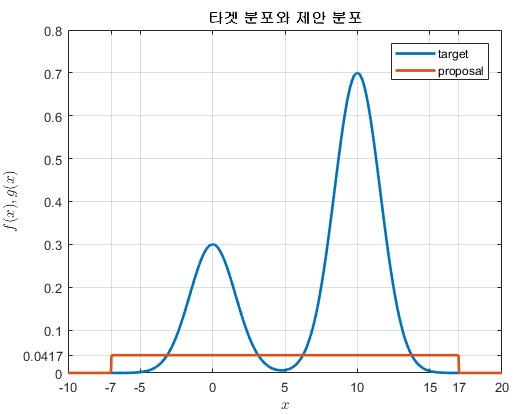
그림 2. 타겟분포와 제안분포
그런 다음 제안 분포에 상수배($M$)를 취해주어 $y$ 축에서도 타겟 분포를 모두 포함할 수 있도록 해주자.
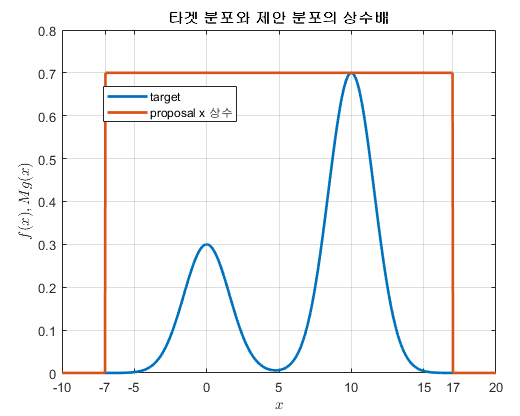
그림 3. 타겟분포와 제안분포에 상수배를 취해주어 타겟 분포를 모두 포함할 수 있도록 한 것.
샘플링 과정
위의 과정에서처럼 제안분포와 적절한 상수를 정했다면 rejection sampling을 수행해보도록 하자.
가장 먼저 해주어야 할 일은 제안분포 $g(x)$에서 샘플 하나($x_0$)를 추출하는 것이다.
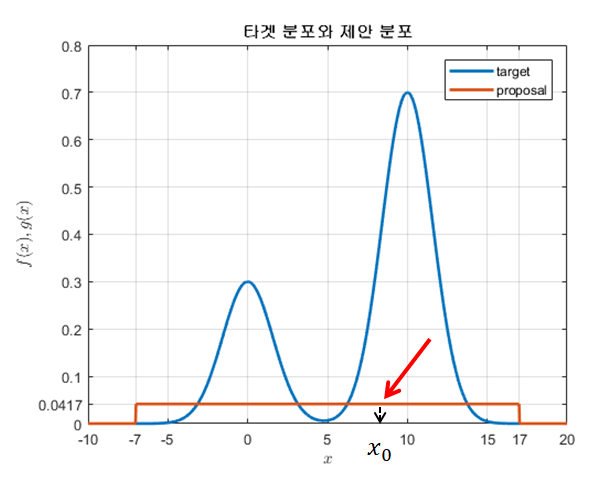
그림 4. 제안분포(여기서는 uniform distribution)에서 샘플 하나를 추출한다.
그런 다음, 타겟 분포 $f(x)$와 상수배를 취한 제안 분포 $Mg(x)$ 의 likelihood를 비교해준다.
즉, 제안분포 $g(x)$로부터 추출한 $x_0$에 대해 $f(x_0)$와 $Mg(x_0)$의 함수 값을 비교해주는 것이다.
이 때, 크기를 비교할 때에는 두 함수값을 나눠줘서 비교하는 방식으로 수행한다.
즉, 아래와 같은 방법으로 비교를 수행하도록 하자.
\[f(x_0)/(Mg(x_0))\]식 (4)를 잘 생각해보면 타겟 분포의 크기가 $Mg(x)$만큼 높으면 1에 가까운 값이 나올 것이고 그렇지 않으면 작은 값이 나올 것이다.
이제 식 (4)의 값을 아래와 같은 정의역으로 정의되는 uniform distribution의 샘플 값과 비교할 수 있도록 하자.
\[x = \lbrace x| 0 \leq x \lt 1\rbrace\]즉, 이것을 그림으로 설명하면 다음과 같다.
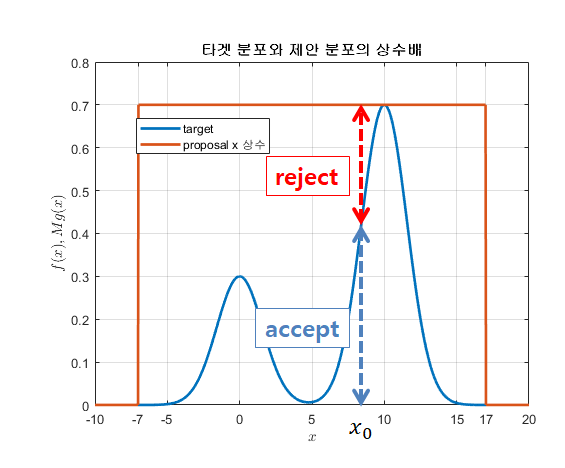
그림 5. 주어진 $x_0$에 대해 likelihood ratio를 비교하여 샘플의 accept/reject 여부를 결정한다.
위의 그림 5에서와 같이 likelihood ratio를 uniform distribution의 출력값과 비교하게 되면 타겟 분포 $f(x)$의 높이가 $Mg(x)$만큼 높은 곳일 수록 accept될 확률이 높다는 것을 알 수 있다.
특히, 비교를 위해 얻은 uniform distribution의 출력값은 0에서 1사이의 값이 랜덤하게 출력된다는 점에 주목해서 생각해보자.
알고리즘을 간략하게 쓰면 다음과 같다.
Set $i = 1$ Repeat until $i=N$
- Sample $x^{(i)} \sim q(x)$ and $u\sim U_{(0,1)}$.
- If $u\lt \frac{f(x^{(i)})}{Mg(x^{(i)})}$, then accept $x^{(i)}$ and increment the counter $i$ by 1. Otherwise, reject.
Rejection sampling 결과
Rejection sample의 결과를 일부 표현하면 다음과 같다.
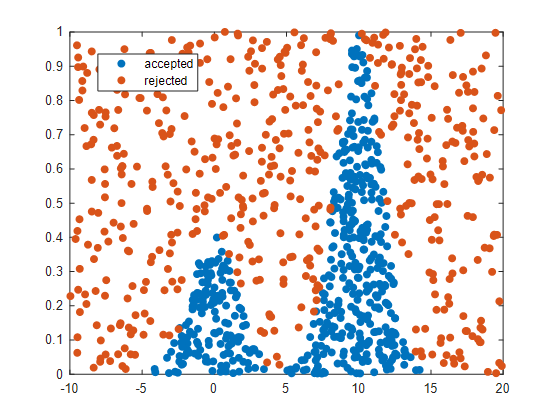
그림 6. accept 된 샘플들과 reject 된 샘플들
그리고 최종적으로 얻어진 샘플들을 원래의 구하고자 했던 타겟 분포 $f(x)$와 함께 히스토그램으로 그리면 다음과 같다.
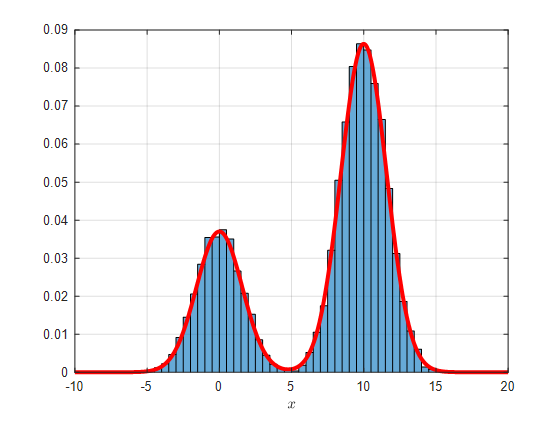
그림 7. 타겟 분포 $f(x)$와 accept된 샘플들을 histogram으로 그린 것.
(다른 그림들과 $y$축의 높이가 다른 것에 주목하자.)
이 결과를 얻기 위한 MATLAB 코드는 아래와 같다.
clear; close all; clc;
rng(1)
n = 500;
target = @(x) 0.3*exp(-0.2 * x.^2) + 0.7 * exp(-0.2 * (x - 10).^2);
xx = linspace(-10,20, 1000);
%% Uniform distribution을 proposal distribution으로 두고 sampling
% 성능에 크게 차이는 없으나 reject되는 sample 수가 조금 차이가 있음.
pseudo_dist2 = @(x) (x>=-10 * x<20) / 30;
figure;
plot(xx, target(xx));
hold on;
plot(xx, pseudo_dist2(xx)*21); % 21은 30 * 0.7을 얘기함. 30은 출력값이 1인 x의 범주, 0.7은 target의 최고 높이.
x_q = (rand(1, n) - 0.5) * 30 + 5; % -10에서 20사이의 uniform distribution
crits = target(x_q) ./ (pseudo_dist2(x_q) * 21);
coins = rand(1, length(crits));
x_p_uniform = x_q(coins<crits);
figure; h = histogram(x_p_uniform,'BinWidth',0.5, 'Normalization','pdf');
hold on; plot(xx, target(xx)/max(target(xx))*max(h.Values))
참고 문헌
- An introduction to MCMC for Maching Learning / C. Andrieu et al., Machine Learning, 50, 5-43, 2003