Deep Nerual Network Transparency
뉴럴네트워크는 전통적으로 “Blackbox” 모델로 생각되어 왔다. 필자 생각에는 그 이유는 크게 두 가지로 보인다. 우선은 뉴럴네트워크가 본래부터 비선형 회귀모델이다보니 입력과 출력간의 관계가 선형적이지 못해 입력이 출력에 어떻게 영향을 주는지 직접적으로 알기 어렵기 때문이다. 또, 최근 들어 딥러닝 기술이 발전하면서 부터는 모델이 스스로 복잡도가 높은 feature에서 분류/회귀에 필요한 feature를 잘 선택할 수 있게되었기 때문에 개발자가 직접 feature를 생성하지 않아도 되었기 때문이다.
이러한 상황속에서 뉴럴네트워크의 성능은 나날이 좋아져가고, 실제 필드에 적용하려는 시도도 많지만 알고리즘이 어떻게 작동하는지 개발자가 정확히 이해하기 어렵다면 필드에 적용했을 때 안정성을 보장하기 어렵기 때문에 뉴럴네트워크가 어떻게 동작하는지 이해하는 연구는 꼭 필요하다고 할 수 있다.
뉴럴네트워크의 동작을 이해하기 위한 연구들은 크게 두 종류로 나눌 수 있다. 첫 번째는 모델 자체를 해석하는 방법이고, 두 번째는 ‘왜 그런 결정을 내렸는지’ 파악하는 방법이다.
![]()
그림 0. 뉴럴네트워크의 동작을 이해하기 위한 여러가지 방법들의 분류
출처: ICASSP2017 Tutorials on Methods for Interpreting and Understanding Deep Neural Networks
이번 글에서 알아보고자하는 Layer-wise Relevance Propagation (이하 LRP)는 두 번째 종류인 ‘왜 그런 결정을 내렸는지’ 파악하는 방법에 속하며, 그 중에서도 decomposition을 이용한 방법이다.
Goal of LRP
LRP는 분해를 통한 설명(explanation by decomposition)을 통해 뉴럴네트워크의 결과물을 이해할 수 있게 도와주는 방법이다.
좀더 상세하게는, 훈련된 뉴럴넷 모델에서 임의의 샘플 $x = (x_1, x_2, \cdots, x_i, \cdots, x_d)$에 대하여 이 뉴럴넷 모델은 $f(x)$라는 출력을 얻는다고 하면,
$d$ 차원 입력 $x$의 각 차원의 relevance score를 계산하는 것이 목적이다.
이 때, 각 차원 i에 대한 relevance score는 다음과 같은 특징을 갖는다.
\[f(x) = \sum_{i=1}^{d}R_i\]이해를 돕기 위해 입력 샘플 $x$가 그림이라고 생각하자. 아래 그림 1의 예시처럼 잘 훈련된 뉴럴네트워크에 수탉 사진을 입력으로 넣고 출력으로 ‘수탉’을 얻는다고 하면,
이 수탉이라는 출력 f(x)1를 얻기 위해 입력 샘플의 각 pixel들이 기여하는 바($R_i$)를 계산하는 방법인 것이다.
아래 그림 1에서 볼 수 있듯이 heatmap이라고 적힌 그림에 각 pixel들의 기여도(relevance score)를 색깔로 표시해두었으며, 수탉의 부리나 머리등을 보고 해당 입력의 클래스가 ‘수탉’임을 출력했다는 것을 알 수 있다.
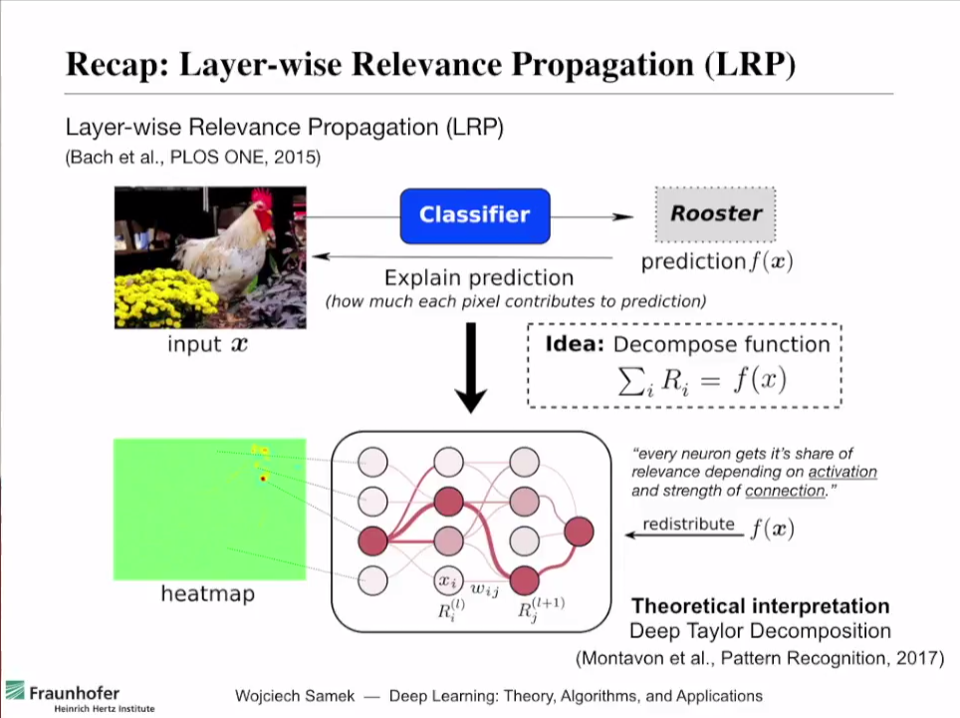
그림 1. LRP가 작동하는 방법 및 결과를 요약한 그림
출처: Explaining Decisions of Neural Networks by LRP. Alexander Binder @ Deep Learning: Theory, Algorithms, and Applications. Berlin, June 2017
The intuition behind it
LRP(Layer-wise Relevance Propagation)의 이름에서 볼 수 있듯이 이 method는 relevance score를 출력단에서 입력단 방향으로 top-down 방식으로 기여도를 재분배 하는 방법이다.
LRP의 기본적인 가정 및 작동 방식은 다음과 같다.
- 각 뉴런은 어느 정도의 기여도(certain relevance)를 갖고 있다.
- 기여도는 top-down 방식으로 각 뉴런의 출력단에서 입력단 방향으로 재분배 된다.
- (재)분배시 기여도는 보존된다.
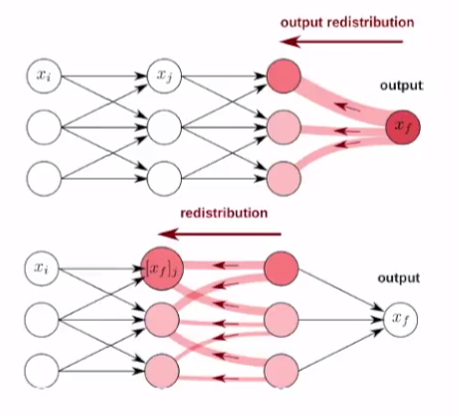
그림 2. relevance score의 분배 과정
출처: Explaining Decisions of Neural Networks by LRP. Alexander Binder @ Deep Learning: Theory, Algorithms, and Applications. Berlin, June 2017
재분배시 기여도가 보존된다는 말을 추가 설명 하자면, 예를 들어 그림 1에서와 같이 특정 사진 입력에 대해 ‘수탉’이라는 분류를 했고 그 출력값(여기서는 확률이라고 할 수 있겠다) $f(x)$가 0.9였다고 하자. 그러면 각 layer의 뉴런들은 0.9라는 출력에 대한 기여도를 모두 조금씩은 갖고 있으며, relevance score를 분배한 후 각 layer에서의 relevance score의 합은 0.9가 되어야 한다는 뜻이다.
Explanation for neural network?
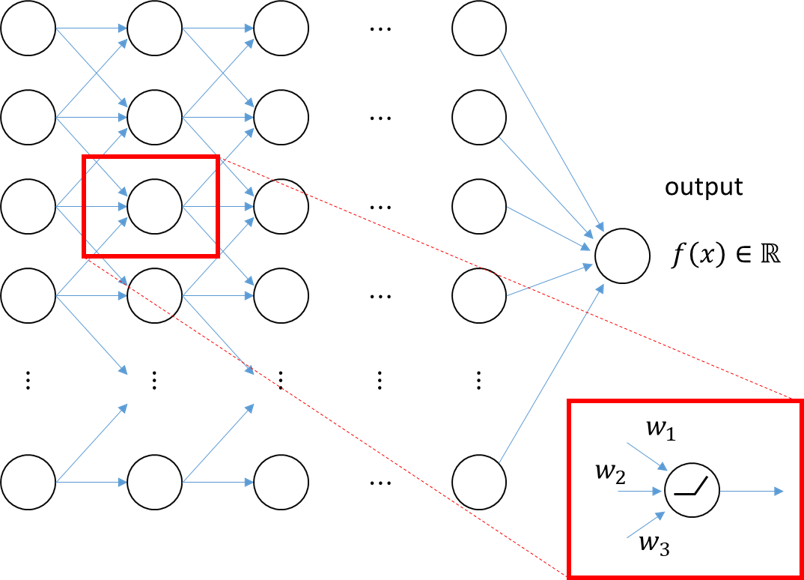
그림 3. 딥뉴럴네트워크의 예측값(prediction)을 잘 분해하기 위해 네트워크 상의 하나 하나의 뉴런 별로 출력값을 분해해볼 수 있다.
이제 우리가 실질적으로 맞닥뜨리게 되는 문제는 이것이다: 딥 뉴럴 네트워크의 예측값 혹은 출력값($f(x)$)을 수학적으로 어떻게 분해하고, 어떻게 ‘기여도’를 정의할 것인가?
이 문제에 대한 해결법은 위에서 설명한 “기본적인 가정 및 작동 방식”에 따라 각 뉴런별로 생각하게 되고, 특히 각 뉴런의 출력과 입력의 관계를 이용해 기여도를 수학적으로 정의하고자 한다.
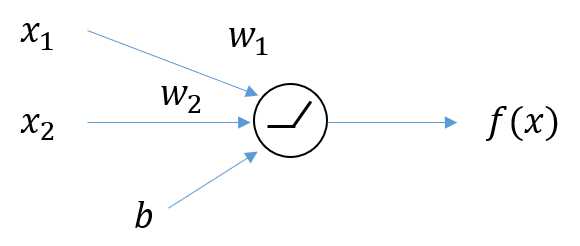
그림 4. 2차원 입력과 1차원 출력을 갖는 뉴런
그림 4에서와 같이 입력 2개를 갖는(즉, weight는 2개, bias는 1개) 기본적인 뉴런 하나를 생각해보자.
수학적으로 relevance score라는 것은 입력의 변화에 따른 출력의 변화 정도로 볼 수 있다.
다시 말해, 그림 4에서 output $f(x)$에 대한 각각의 입력 $x_1, x_2$의 기여도는 다음과 같이 표현될 수 있다.
\[\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}\]그러므로, 어떻게든 아래와 같이 $f(x)$와 $\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}$ 간의 관계를 설명할 수 있는 적절한 식을 도출할 수 있다면,
출력을 relevance score로 분해하여 생각할 수 있게 되는 것이다.
LRP에서는 Taylor Series를 도입한다.
Taylor Series
임의의 매끄러운 함수 $f(x)$ 및 실수 $a$에 대해 $f(x)$의 Taylor Series는 다음과 같다.
\[f(x) = \sum_{n=0}^{\infty}\frac{f^{(n)}(a)}{n!}(x-a)^n\] \[=f(a) + \frac{f'(a)}{1!}(x-a) + \frac{f''(a)}{2!}(x-a)^2 + \frac{f'''(a)}{3!}(x-a)^3 + \cdots\]여기서 error term “$\epsilon$”을 이용해 first-order Taylor series를 쓰면 다음과 같다.
\[f(x) = f(a) + \frac{d}{dx}f(x)\big|_{x=a}(x-a) + \epsilon\]다변수 함수의 경우에는 Taylor 급수는 다음과 같다.

그림 5. 다변수 함수의 Taylor 급수. 출처: Wikipedia
즉, d 차원 input에 대해서는 다음과 같이 first-order Taylor series를 쓸 수 있다.
\[f(\pmb{x}) = f(\pmb{a}) + \sum_{p = 1}^{d}\frac{\partial \pmb{f}}{\partial x_p}\big|_{\pmb{x}=\pmb{a}}(\pmb{x} - \pmb{a}) + \epsilon\]위 식에서 우변의 두 번째 term이 의미하는 것이 바로 $x_p$가 변했을 때 $f(x)$는 얼마나 변했는가이다.
테일러 급수 수식의 ‘적절한’ 변형
식 (6)은 우리에게 꼭 필요한 기능인 “출력을 relevance score로 분해해주는 기능”을 할 수 있게 도와주지만, 불필요한 term이 두 가지 있다. $f(a)$와 $\epsilon$이 그것이다.
$f(a)$는 Taylor series의 특성을 통해 $f(a) = 0$인 $a$를 수학적으로 찾고, 그 지점으로부터 함수를 근사화 함으로써 $0$으로 만들어버릴 수 있다. 또, $\epsilon$은 ReLU 활성화 함수의 특성을 이용해 $0$으로 만들어버릴 수 있다.
만약 그렇게 할 수 있다면 다음과 같이 출력 $f(x)$는 relevance score만으로 분해가능하다.
\[f(x) = f(a) + \sum_{i=1}^{d}\frac{\partial f}{\partial x_i}\big|_{x_i = a_i}(x_i-a_i) + \epsilon\] \[= \sum_{i=1}^{d}\frac{\partial f}{\partial x_i}\big|_{x_i = a_i}(x_i-a_i)\] \[= \sum_{i=1}^{d}R_i\]ReLU의 특성을 통해 epsilon = 0임을 확인해보자.
그림 4와 같은 입력 2개와 출력 하나를 갖고, 활성화 함수가 ReLU인 뉴런의 작동은 수학적으로 다음과 같이 기술 할 수 있다.
\[f(x) = \max\left(0, \sum_{i=1}^{2}w_i x_i + b\right)\] \[= \begin{cases} 0 & \text{case i) when $\sum_{i=1}^{2}w_ix_i + b \leq 0$} \\ \sum_{i=1}^{2}w_ix_i + b & \text{case ii) when $\sum_{i=1}^{2}w_ix_i + b > 0$} \end{cases}\]식 (11)에서 볼 수 있듯이 case i)인 경우에는 우리가 더 이상 신경쓸 이유가 없고, case ii)에 대해서 수식 전개를 계속해나가도록 하자.
한편, 식 (10)의 $f(x)$는 식 (7)에서와 같이 $f(x)$는 Taylor 급수로도 나타낼 수 있다. 따라서,
\[f(x) = \sum_{i=1}^{2}w_ix_i + b = f(a) + \sum_{i=1}^{d}\frac{\partial f}{\partial x_i}\big|_{x_i=a_i}(x_i-a_i) + \epsilon\]여기서 식 (12)를 잘 보면, $f(x)$는 다음과 같이 쓸 수 있다.
\[f(x) = w_1x_1+w_2x_2+b\]따라서, $\frac{\partial f}{\partial x_i}$는 다음과 같다.
\[\frac{\partial f(x)}{\partial x_1}= w_1, \frac{\partial f(x)}{\partial x_2} = w_2\]또, 다음과 같이 2차 이상의 편미분 계수는 모두 0이다.
\[\frac{\partial ^2 f(x)}{\partial x_1 ^2} = 0, \space \frac{\partial^2 f(x)}{\partial x_1 \partial x_2} = 0, \space \cdots\]따라서, 식 (12)에서 Taylor Series로 씌여진 식에서 $\epsilon=0$임을 알 수 있다.
그러므로, 식 (12)를 다시 쓰면 다음과 같다.
\[f(x) = \sum_{i=1}^{2}w_ix_i+b = f(a) + \sum_{i=1}^{2}w_i(x_i-a_i)\]적절한 a를 찾는 방법
테일러 급수를 이용해 함수를 근사화(approximate) 할 때 근사화를 시작할 점 $x=a$는 어느 위치여도 관계 없이 무한한 항을 다 더해줄 수 만 있다면 정확하게 그 함수를 근사화할 수 있다.
다만 LRP에서는 식 (8)에서 보았듯이 $f(a)=0$이라는 제약조건이 존재하므로, 이 조건을 만족시키는 a를 찾으면 되고 여전히 무수히 많은 $a$가 해당 제약조건을 만족할 수 있다.
이번에 소개할 방법은 참고문헌 (Explaining NonLinear Classification ~)에서 소개하는 $w^2$-rule이다.
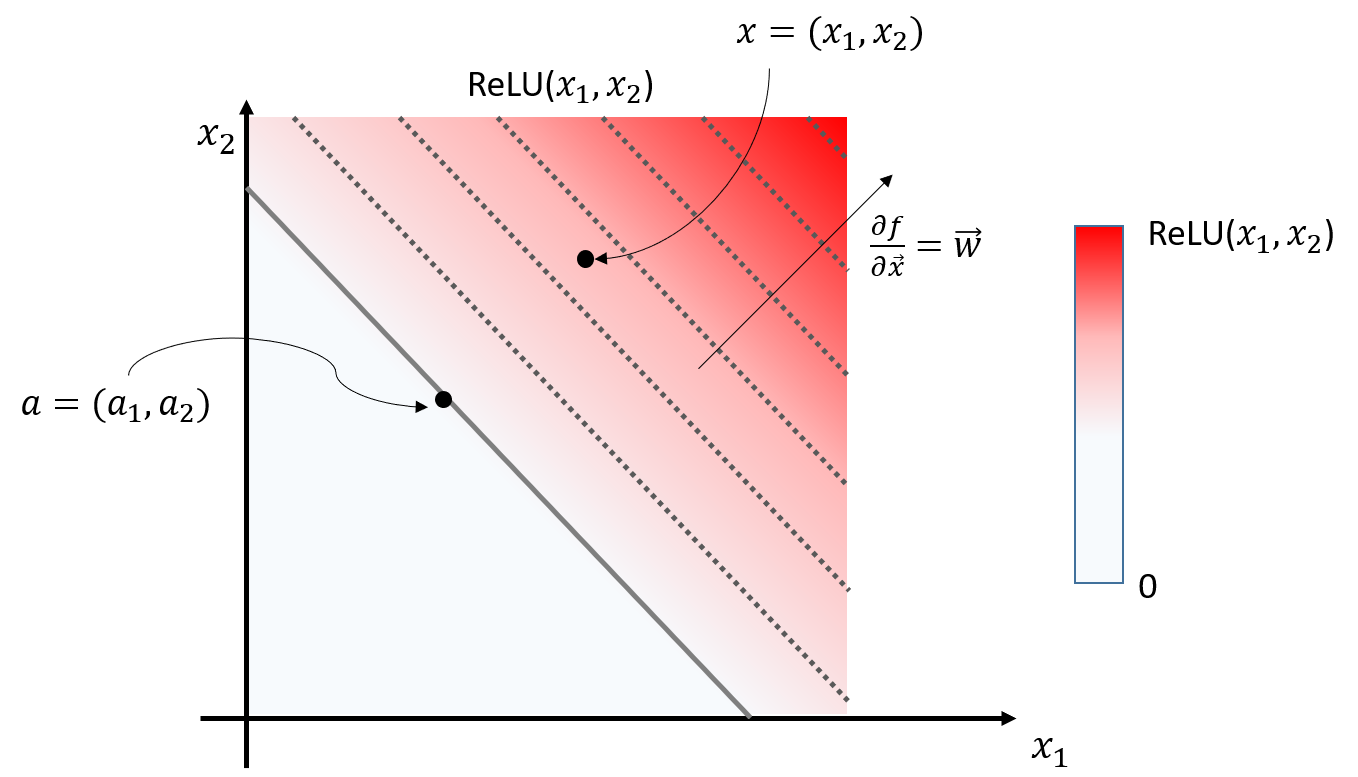
그림 6. 하나의 뉴런에서, 두 개의 입력값과 ReLU 통과 후의 출력값(색깔)을 도시한 그림
그림 6은 그림 4에서 표현한 뉴런과 같이 두 개의 입력값과 하나의 출력값을 가지는 뉴런의 입출력 관계를 나타내고 있다. 입력 $x_1, x_2$는 우리가 입력한 것이니 알고 있는 값이고, 그 출력값 $f(x_1, x_2) = ReLU(x_1, x_2)$는 뉴럴네트워크 모델에 의해 결정된 값이다. 출력 값은 색깔로 표시되었으며, 흰색에 가까울 수록 0에 가깝고 빨간색에 가까울 수록 그 값이 크다. 실선으로 표시되어 있는 지점은 모든 값이 0인 지점이고, 점선으로 표시되어 있는 지점은 동일한 값을 갖는 등고선이다.
그림 6에서 볼 수 있는 것 처럼 $w^2$-rule이 말하는 적절한 $a$는 출력값이 0 (즉, $f(a) = 0$)이면서 입력 $x = (x_1, x_2)$에 가장 가까운 지점이다.
$w^2$-rule을 따를 때, $a$를 계산하기 위해 다음과 같은 과정을 거칠 수 있다.
일단 그림 6에서 화살표의 의미를 생각해보면 $\vec{a}$와 $\vec{x}$는 다음과 같은 관계를 갖는다.
\[\vec{a} - \vec{x} = t\vec{w}\]즉, $\vec{a}$와 $\vec{x}$를 빼준 벡터가 $\vec{w}$의 실수배가 되어야 한다는 점이다.
이 식을 약간 변경하면,
\[\vec{a} = \vec{x} + t\vec{w}\]가 된다.
또, 우리의 제약 조건($f(a) = 0$)에 따라,
\[f(\vec{a}) = \sum_{i=1}w_ia_i+b = 0\]이다.
식 (19)에 식 (18)을 대입하면,
\[f(\vec{a}) = \sum_{i=1} w_i(x_i+tw_i) + b = 0\] \[= \sum_{i=1}w_ix_i + t\sum_{i}w_i^2 + b = 0\] \[\therefore t = - \frac{\sum_i w_ix_i + b}{\sum_i w_i^2}\]식 (22)를 식 (18)에 다시 대입하면,
\[a_i = x_i - \left( \frac{\sum_iw_ix_i + b}{\sum_iw_i^2} \right)w_i\]식 (23)을 이용하면 $f(x)$를 다음과 같이 쓸 수 있다.
\[f(x) = 0 + \sum_i w_i\left(\frac{\sum_iw_ix_i + b}{\sum_i w_i^2}\right)w_i + 0\] \[=\sum_i\left(\frac{\sum_iw_ix_i + b}{\sum_i w_i^2}\right)w_i^2 = \sum_iR_i\]참고로, $w^2$-rule 외에도 $z$-rule, $z^+$-rule 등 여러가지 Rule이 있으니, 이것은 참고문헌 (Explaining NonLinear ~)를 참고하도록 하자.
Relevance Propagation Rule 정리
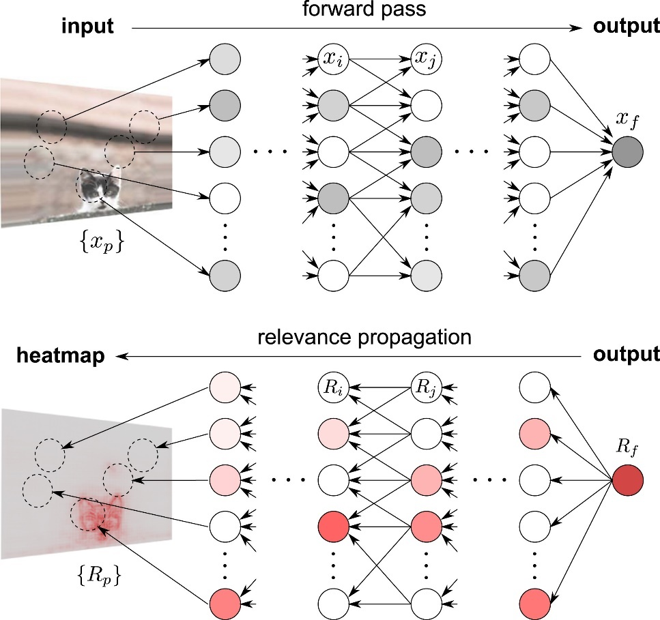
그림 7. Forward Pass, Relevance Propagation을 한 그림에 모두 표시한 것.
지금까지 정리한 내용에 따르면 적절한 $a$를 찾음으로써, 하나의 뉴런의 출력 $f(x)$는 다음과 같이 분해될 수 있다는 것을 알 수 있었다.
\[f(x) = \sum_i R_i\]지금까지 하나의 뉴런에 대해 알아온 내용을 그림 7에서처럼 전체 뉴럴 네트워크에 적용시키고자 한다면 다음과 같은 과정을 통해 진행할 수 있다.
그림 7의 상단에서 처럼 특정 입력 ${x_p}$에 대한 뉴럴네트워크의 최종 출력이 $x_f$라고 하자 (forward pass).
그런 다음 출력단의 뉴런이 가지는 relevance score $R_f$를 $x_f$와 같게 둔 다음 그 전 layer들로 propagation을 시킨다고 하자.
즉, $f(x) = \sum_i R_i$에서 처럼 $R_f = \sum_i R_i$로 생각해서 그 전 layer로 계속해서 뒤로 propagation 시켜나가면, 뉴럴네트워크 상의 모든 뉴런들의 relevance score를 계산할 수 있게 된다.
참고용 Python 코드
# -------------------------
# Feed-forward network
# -------------------------
class Network:
def __init__(self,layers):
self.layers = layers
def forward(self,Z):
for l in self.layers: Z = l.forward(Z)
return Z
def gradprop(self,DZ):
for l in self.layers[::-1]: DZ = l.gradprop(DZ)
return DZ
def relprop(self, R):
for I in self.layers[::-1]: R = I.relprop(R)
return R
# -------------------------
# ReLU activation layer
# -------------------------
class ReLU:
def forward(self,X):
self.Z = X>0
return X*self.Z
def gradprop(self,DY):
return DY*self.Z
def relprop(self, R):
return R
# -------------------------
# Fully-connected layer
# -------------------------
class Linear:
def __init__(self, weight, bias):
self.W = weight
self.B = bias
def forward(self,X):
self.X = X
return np.dot(self.X,self.W)+self.B
def gradprop(self,DY):
self.DY = DY # DY는 target을 넣으면 됨. Desired Y
return np.dot(self.DY,self.W.T)
class NextLinear(Linear): # implementing Z+ rule
def relprop(self,R):
V = np.maximum(0,self.W) # V는 W_ij^+를 의미함.
Z = np.dot(self.X,V)+1e-9; S = R/Z
C = np.dot(S,V.T); R = self.X*C
return R
class FirstLinear(Linear): # implementing Zbeta rule
def relprop(self,R):
W,V,U = self.W,np.maximum(0,self.W),np.minimum(0,self.W)
# X,L,H = self.X,self.X*0+utils.lowest,self.X*0+utils.highest
X,L,H = self.X,self.X*0+(-1),self.X*0+(1.0)
Z = np.dot(X,W)-np.dot(L,V)-np.dot(H,U)+1e-9; S = R/Z
R = X*np.dot(S,W.T)-L*np.dot(S,V.T)-H*np.dot(S,U.T)
return R
# Network 구조 입력
nn = Network([
FirstLinear(final_W1, final_b1),ReLU(),
NextLinear(final_W2, final_b2),ReLU(),
NextLinear(final_W3, final_b3),ReLU(),
NextLinear(final_W4, final_b4),ReLU(),
NextLinear(final_Wh, final_bh),ReLU(),
])
rand_num = np.random.permutation(n_total)
X = total_x[rand_num,:] # Input
T = total_y[rand_num,:] # Target
Y = nn.forward(X) # Output
S = nn.gradprop(T)**2
Y = nn.forward(X)
D = nn.relprop(Y*T)
참고문헌
- Explaining NonLinear Classification Decisions with Deep Taylor Decomposition, Montavon et al., 2015
- Explaining Decisions of Neural Networks by LRP. Alexander Binder @ Deep Learning: Theory, Algorithms, and Applications. Berlin, June 2017
- ICASSP2017 Tutorials on Methods for Interpreting and Understanding Deep Neural Networks
-
여기서 이 분류기가 수탉이냐 아니냐를 판단하는 binary classifier라면 출력 f(x)는 sigmoid 함수의 출력으로, 다중 클래스 분류기라면 softmax의 출력을 쓸 수 있다. ↩