※ 본 포스팅은 Andrew Ng 교수님의 강의를 정리한 것임을 밝힙니다.
Python 라이브러리를 이용한 딥러닝 학습 알고리즘에 관련된 tutorial들에서 거의 대부분 optimization을 수행할 때 Gradient Descent 대신에 ADAM Optimizer를 이용해 Optimziation을 하라고 한다.
과연 어떤 부분에서 ADAM이 Gradient Descent에 비해 좋길래 거의 대부분의 문헌에서 ADAM을 추천하고 있는지 그 배경에 대해 알아보도록 하자.
Prerequisites
본 포스팅에 대해 이해하기 위해선 아래의 내용에 대해 알고 오시는 것이 좋습니다.
Gradient Descent의 문제
Gradient descent를 이용해 비용함수(혹은 Error)를 최소화해주고자 하면 어떤 경우에는 수렴 속도가 굉장히 느릴 때가 있다.
이런 경우 step size(혹은 learning rate)을 키워주면 수렴 속도가 빨라지는 경우가 있지만, 어떤 경우는 종종 아래의 그림 1과 같이 비용함수의 형태 특성 상 특정 parameter에 대해 진동하면서 수렴하다보니 수렴 속도가 느려지는 경우가 있다. 이럴 때에는 자칫 잘못하면 비용함수가 발산해버리는 경우가 왕왕 생기기 때문에 학습 속도가 느리더라도 하는 수 없이 기다릴 수 밖에 없을 것이다.
(그림 1에서는 b라는 parameter에 대해 진동하면서 서서히 최솟값으로 수렴하고 있다.)
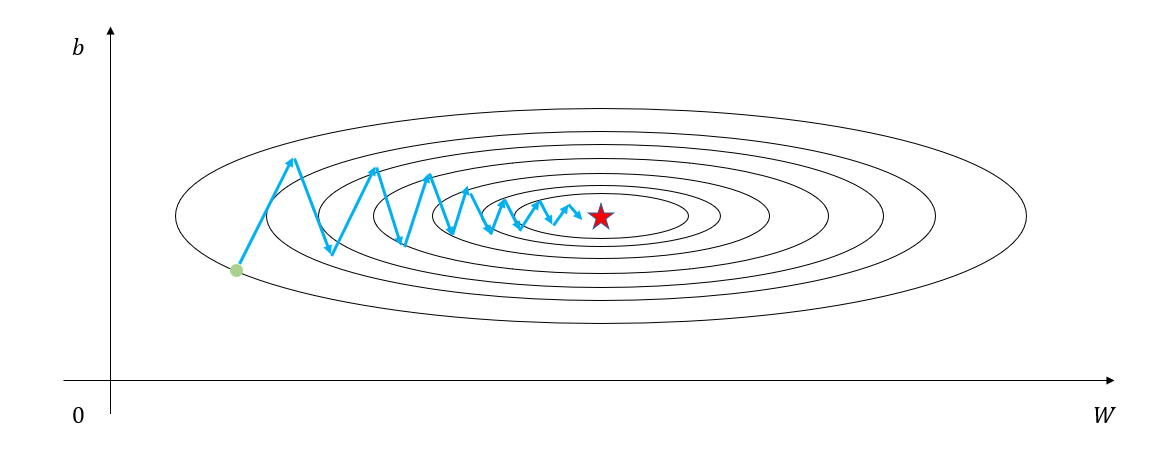
그림 1. 비용함수 최소화 시 특정 parameter에 대해 진동하면서 수렴하는 경우
이렇듯 비용함수에 대한 진동이 발생하는 이유는 gradient의 개념 자체가 등고선에 수직한 방향으로 벡터가 만들어지기 때문이다.
그렇다면 이런 특성을 감안했을 때, 우리가 원하는 것을 다시 정리하자면 그림 1에서 세로 방향으로는 천천히 수렴하고 가로 방향으로는 빨리 수렴할 수 있도록 하는 것이다.
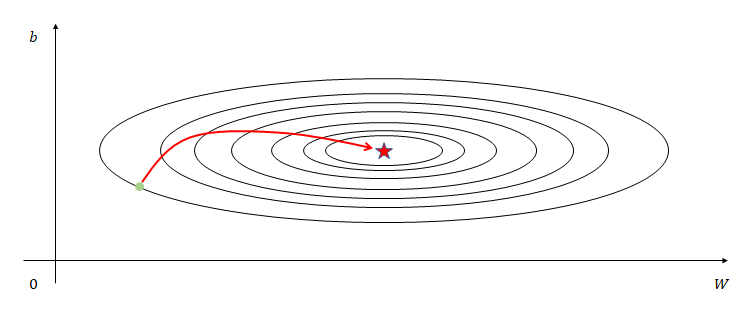
그림 2. 우리가 원하는 수렴 경로
Gradient Descent with Momentum
Momentum의 개념을 도입한 Gradient Descent는 iteration에 따라 방향이 반대로 계속 바뀌어가는 형태의 경로를 거쳐왔을 때에는 해당 방향으로 update하는 변화량이 점차 작아지고, iteration에 따라 방향이 계속 유지되어가면 가속을 붙여주는 방식의 update method라고 할 수 있다.
이 method의 이름을 Momentum이라고 하고 pseudo-code를 통해 알고리즘을 우선 보도록 하자.
여기서는 모델의 파라미터가 $W$, $b$ 두 개라고 생각해보자.
또, subscript로 쓴 $(t)$는 $t$ 번째 iteration에서 계산한 것이라는 걸 말해준다고 하자.
[Momentum 알고리즘]
Initialize $V_{dw(0)} = \vec 0$, $V_{db(0)} = \vec 0$
(여기서 $V_{dw(0)}$의 차원은 $W$의 차원과 같고, $V_{db(0)}$의 차원은 $b$의 차원과 같음.)
$t$ 번째 iteration에서:
$\quad$ 현재 batch에 대한 $dW_{(t)}$, $db_{(t)}$을 계산함.
$\quad$ 그 뒤 아래의 term들을 계산함.
\[V_{dw(t)} =\beta_1 V_{dw(t-1)} + (1-\beta_1)dW_{(t)}\] \[V_{db(t)} = \beta_1 V_{db(t-1)} + (1-\beta_1)db_{(t)}\]$\quad$ Weight, bias 업데이트:
\[W := W - \alpha V_{dw(t)}\] \[b:= b - \alpha V_{db(t)}\]여기서 $\alpha$는 learning rate이다. 또, $dW$는 전체 로스 $L$에 대해 $\partial L / \partial W$로 손실 함수 $L$을 가중치 $W$로 미분한 값을 의미한다.
Momentum 알고리즘의 핵심은 식 (1)과 식 (2)인데, 형태는 거의 같기 때문에 식 (1)을 조금 더 풀어서 생각해보도록 하자.
식 (1)은 재귀적으로 계산되는 term인데, iteration 1부터 차근히 살펴보면 다음과 같을 것이다.
\[V_{dw(1)} = \beta_1 V_{dw(0)} + (1-\beta_1)dW_{(1)}\]두 번째 iteration에서는,
\[V_{dw(2)} = \beta_1 V_{dw(1)} + (1-\beta_1)dW_{(2)}\] \[=\beta_1(\beta_1 V_{dw(0)}+(1-\beta_1)dW_{(1)})+ (1-\beta_1)dW_{(2)}\] \[=\beta_1^2V_{dw(0)}+ \beta_1(1-\beta_1)dW_{(1)}+(1-\beta_1)dW_{(2)}\]세 번째 iteration에서는 다음과 같다.
\[V_{dw(3)} = \beta_1 V_{dw(2)}+ (1-\beta_1)dW_{(3)}\] \[= \beta_1 \left\lbrace\beta_1^2V_{dw(0)}+ \beta_1(1-\beta_1)dW_{(1)}+(1-\beta_1)dW_{(2)}\right\rbrace+ (1-\beta_1)dW_{(3)}\] \[=\beta_1^3V_{dw(0)}+ \beta_1^2(1-\beta_1)dW_{(1)}+\beta_1(1-\beta_1)dW_{(2)}+(1-\beta_1)dW_{(3)}\]이를 일반화해서 생각해보면 $k$ 번째 iteration에서는 다음과 같을 것이다.
\[V_{dw(k)} = \beta_1^k V_{dw(0)}+\beta_1^{k-1}(1-\beta_1) dW_{(1)}+\beta_1^{k-2}(1-\beta_1) dW_{(2)}+\cdots +\beta_1^0(1-\beta_1)dW_{(k)}\] \[=\beta_1^kV_{dw(0)}+\sum_{i=1}^{k}\beta_1^{k-i}(1-\beta_1)dW_{(i)}\]보통 $V_{dw(0)}$은 0으로 초기화하므로,
\[식(13) \Rightarrow \sum_{i=1}^{k}\beta_1^{k-i}(1-\beta_1)dW_{(i)}\]이다.
여기서 $\beta_1$ 값은 0.9 정도로 잡는게 보통이다.
이제, 이 Momentum의 의미를 다시 생각해보기 위해 식 (11)을 한번 다시 보도록 하자.
식 (11)을 보면 현재의 속도 $V_{dw(3)}$은 과거의 $dW$들에 영향을 받는데, 현재 iteration 대비 이전 값일 수록 $\beta_1$ 값이 더 많이 곱해져있어서 최근의 속도 값들이 더 큰 영향을 주는 것을 알 수 있다. $dW_{(i)}$는 생각해보면 $i$ 번째 시점의 순간적인 힘에 비유할 수 있으므로 과거의 영향은 갈수록 줄어든다는 걸 볼 수 있다.
즉, Gradient의 진행이 그림 1에서와 같았다면 위 아래로 변하는 b축 gradient factor들은 더하기 빼기 해주게 되면서 서서히 속도가 0으로 가까워 질 것이고, 오른쪽으로 계속 진행되는 gradient의 W축 방향 factor들은 계속 더해주게 되어 관성이 작용하는 것 처럼 속도가 점점 붙을 것이다.
RMSProp
RMSProp 알고리즘은 Root Mean Square Propagation의 줄임말로써 Geoffrey Hinton이 제안한 알고리즘이다. Coursera의 강의 도중 처음으로 제안된 알고리즘으로도 유명한데, Academic paper로 공식적으로 발표한 적은 없지만 상당히 유명한 알고리즘으로 자리매김하고 있다.
RMSProp은 Momentum을 이용한 Gradient와 사용 방식은 거의 유사한데, Gradient의 방향을 이용하지 않고 그 크기만을 이용해 업데이트 해주고자 하는 각 parameter에 대한 학습 속도를 조절한다.
우선 RMSProp 알고리즘을 보도록 하자.
[RMSProp 알고리즘]
Initialize $S_{dw(t)} = \vec{0}$, $S_{db(t)} = \vec{0}$
(여기서 $S_{dw(0)}$의 차원은 $W$의 차원과 같고, $S_{db(0)}$의 차원은 $b$의 차원과 같음.)
On iteration $t$:
$\quad$ 현재 batch에 대한 $dW_{(t)}$, $db_{(t)}$을 계산함.
$\quad$ 그 뒤 아래의 term들을 계산함.
\[S_{dw(t)} =\beta_2 S_{dw(t-1)} + (1-\beta_2)dW_{(t)}^2\] \[S_{db(t)} = \beta_2 S_{db(t-1)} + (1-\beta_2)db_{(t)}^2\]$\quad$ Weight, bias 업데이트:
\[W := W - \alpha \frac{dW_{(t)}}{\sqrt{S_{dw(t)}}+\epsilon}\] \[b:= b - \alpha \frac{db_{(t)}}{\sqrt{S_{db(t)}}+\epsilon}\](여기서 $\epsilon$은 $S$가 매우 작아졌을 때 0으로 나누는 것을 방지하기 위한 값으로 1보다 매우 작은 양수이다.)
Momentum 알고리즘과 RMSProp 알고리즘의 차이는 $S_dw$ 혹은 $S_db$라는 term에 있다고 할 수 있다.
가령 그림 1과 같은 상황에서 RMSProp 알고리즘을 적용시켜준다고 하면, iteration이 진행됨에 따라 gradient의 크기가 $W$ 방향으로는 크지 않고 $b$ 방향으로는 큰 것을 알 수 있다.
따라서, $S_{dw}$는 값이 작을 것이고 $S_{db}$는 값이 클 것임을 예상할 수 있다.
그래서 식 (17)과 식 (18)에서 $S_{dw(t)}$와 $S_{db(t)}$로 나눠주는 과정은 $W$ 방향으로는 더 빨리 학습이 진행되고, $b$ 방향으로는 더 천천히 학습이 진행되도록 조정하는 과정인 것이다.
다시 말해 RMSProp이 가지는 의의는 각 parameter 별로 적절히 learning rate의 크기를 조절해줄 수 있다는데 있다.
ADAM(Adaptive Moment Estimation)
ADAM은 Gradient Descent with Momentum과 RMSProp을 동시에 사용한 것이다.
ADAM의 알고리즘을 보면 바로 이 말이 무엇인지 이해할 수 있을 것이다.
[ADAM 알고리즘]
Initialize $V_{dw(0)} = \vec 0$, $V_{db(0)} = \vec 0$, $S_{dw(0)} = \vec{0}$, $S_{db(0)} = \vec{0}$
(여기서 $V_{dw(0)}$와 $S_{dw(0)}$의 차원은 $W$의 차원과 같고, $V_{db(0)}$와 $S_{db(0)}$의 차원은 $b$의 차원과 같음.)
$t$ 번째 iteration에서:
$\quad$ 현재 batch에 대한 $dW$, $db$을 계산함.
$\quad$ 그 뒤 아래의 term들을 계산함.
\[V_{dw(t)} =\beta_1 V_{dw(t-1)} + (1-\beta_1)dW_{(t)}\] \[V_{db(t)} = \beta_1 V_{db(t-1)} + (1-\beta_1)db_{(t)}\] \[S_{dw(t)} =\beta_2 S_{dw(t-1)} + (1-\beta_2)dW_{(t)}^2\] \[S_{db(t)} = \beta_2 S_{db(t-1)} + (1-\beta_2)db_{(t)}^2\]$\quad$ Weight, bias 업데이트:
\[W := W - \alpha V_{dw(t)}/\sqrt{S_{dw(t)}+\epsilon}\] \[b:= b - \alpha V_{db(t)}/\sqrt{S_{db(t)}+\epsilon}\]ADAM의 원래 논문(King & Ba, 2015)에서는 다음과 같이 $\beta_1$, $\beta_2$, $\epsilon$의 값을 추천해주고 있다.
\[\begin{cases}\beta_1: 0.9 \\ \beta_2: 0.99 \\ \epsilon: 10^{-8}\end{cases}\]Bias Correction
앞서 확인한 Gradient Descent with Momentum, RMSProp, ADAM은 모두 $beta<1$ 값을 이용해 이전 값들을 서서히 잊어가는 Exponentially Weighted Moving Average (EWMA)의 일종이라고 할 수 있다.
EWMA는 일반적으로 아래와 같은 수식으로 쓸 수 있다.
데이터 포인트를 $x(t)$라고 하고, $v(0)=0$이라고 했을 때,
\[v(t) := \beta v(t-1) + (1-\beta)x(t)\]이다.
일반적으로 $\beta$값은 1보다는 작은 값인데 1에 가까워질 수록 smoothing이 더 많이 된 것이라는 것을 알 수 있다.
그림 N. 여러가지 beta값에 따른 EWMA의 결과
위의 그림 N을 보면 알수있는 것이지만 smoothing이 많이 필요한 경우 $\beta$값을 키워주게 되면 초기 time의 smoothing 결과가 원래의 데이터 포인트들에 비해 낮게 나온다는 것을 알 수 있다.
이 에러를 잡기 위해 각 iteration의 출력값 $v(t)$을 보정해줄 수 있으며, 보정 식은 다음과 같다.
\[v(t) := v(t) / (1-\beta^t)\]여기서 $t$는 현재 iteration 혹은 time 이다.
그림 M. 보정 전(빨강) 보정 후(초록)
참고 문헌
- ADAM: A Method for Stochastic Optimization, Kingma & Ba, ICLR, 2015