칼만필터를 이용한 마우스 움직임 Tracking. 만약 내 손이 심하게 떨고 있을 때, 칼만 필터는 떨지 않았을 경우의 마우스 궤적을 추정해주는데 쓰일 수 있다.
Prerequisites
본 페이지에서 소개하는 칼만필터를 이해하기 위해서는 다음의 내용에 대해 알고 오시는 것이 좋습니다.
칼만 필터 소개
칼만 필터란?
- 소개 필요
칼만 필터 예시: 물체의 궤적 추정
칼만 필터에 대해 수학적으로 논의하기에 앞서 칼만 필터를 이용해 무엇을 할 수 있는지 알아보도록 하자.
칼만필터를 이용하면 물체를 추적 할 때 지금까지의 궤적에 기반해 다음번 물체의 위치를 추정하는데 사용할 수 있다.
쉽게 설명하면, 아래 그림에서 볼 수 있듯이 지금까지 t = 0, 1, 2이라는 시간 순서에 따라 궤적을 얻었다고 해보자.
그러면 t = 3 일 때는 물체가 어디에 있다고 보는 것이 가장 타당할까? 아마도 초록색 네모가 가장 타당한 다음 번 위치라고 생각할 수 있을 것이다.
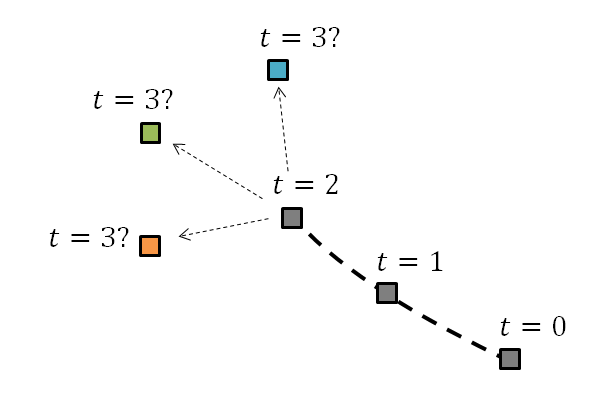
그림 1. 지금까지의 궤적에 따르면 t=3에서는 어떤 곳에 위치할 확률이 가장 높을까?
이것을 조금 더 응용한 사례가 아래 영상에 구현되어 있다.
아래 영상에서는 칼만 필터를 이용한 공의 궤적에 대한 추정을 보여주고 있다. 빨간색 원의 크기가 클 수록 다음 번 스텝에 대한 예측이 불확실하다는 것을 의미한다.
정규 분포에 관한 두 가지 연산: 합성곱과 곱
우리가 다루고자 하는 칼만필터는 정규 분포를 이용해 모든 상태와 동작을 서술한다.
또, 칼만 필터는 "시간에 따른 상태의 변화"에 대해 다루고 있기 때문에 우리는 정규 분포로 표현한 상태의 변화에 대해 미리 알아둘 필요가 있으며,
상태의 변화는 합성곱(convolution)과 곱(product) 이라는 두 연산을 통해 표현할 수 있다. (자세한 논의는 아래에서 더 진행하도록 하겠다.)
두 연산 과정에 대해 자세한 증명은 Products and Convolutions of Gaussian Probability Density Functions라는 문헌에서 참고하길 바라며, 우리는 이 연산들의 결과에 대해서만 확인하고자 한다.
합성곱과 곱 모두 두 정규분포에 대해 다루고 있기 때문에 각각의 정규분포 함수를 다음과 같이 정의하고자 한다.
\[\mathcal{N}_1(x;\mu_1, \sigma_1^2) = \frac{1}{\sqrt{2\pi \sigma_1^2}}\exp\left(-\frac{(x-\mu_1)^2}{2\sigma_1^2}\right)\] \[\mathcal{N}_2(x;\mu_2, \sigma_2^2) = \frac{1}{\sqrt{2\pi \sigma_2^2}}\exp\left(-\frac{(x-\mu_2)^2}{2\sigma_2^2}\right)\]참고로, 앞으로는 정규 분포를 표현할 때는 $\mathcal{N}$이라는 기호를 이용하겠으며, $\mathcal{N}(x;\mu_1, \sigma_1^2)$라고 되어 있으면, 정의역이 $x$이고 파라미터는 $\mu_1, \sigma_1^2$와 같이 평균, 분산이 주어진 것이라는 의미로 사용하고자 한다.
두 정규 분포의 합성곱(convolution)
먼저 확인해 볼 상태 변화 연산은 두 정규 분포의 합성곱(convolution)이다.
합성곱(convolution)은 임의의 두 함수 $f(t)$와 $g(t)$에 대해 다음과 같이 정의되는 연산이다.
\[f(t) \circledast g(t) = \int_{-\infty}^{\infty}f(\tau)g(t-\tau)d\tau\]수식을 설명하자면, 합성곱은 하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간에 대해 적분하여 새로운 함수를 얻는 수학 연산자라고 할 수 있는데,
그림으로 보자면 다음과 같이 어떤 함수에 다른 함수를 슬라이딩해가면서 곱해 얻은 결과 값들을 가지고 새로운 함수를 얻는 것이라고 할 수 있다.
좀 더 자세한 논의는 위키피디아를 참고해보는 것도 좋을 것 같다(https://en.wikipedia.org/wiki/Convolution).
아래와 같은 두 정규 분포에 대해서,
\[\mathcal{N}_1(x;\mu_1, \sigma_1^2)\text{ , }\mathcal{N}_2(x;\mu_2, \sigma_2^2)\notag\]합성곱 결과는 다음과 같다.
\[\mathcal{N}_1 \circledast \mathcal{N}_2 = \mathcal{N}(x; \mu_1+\mu_2, \sigma_1^2 +\sigma_2^2)\]
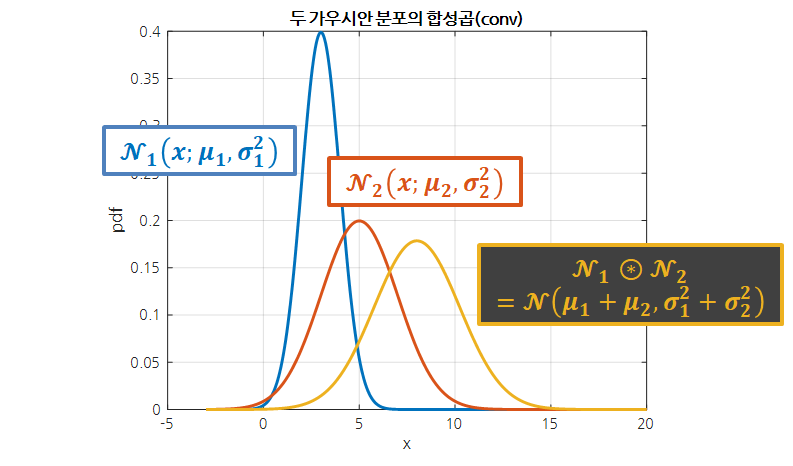
그림 2. 두 정규 분포의 합성곱(convolution)
합성곱은 수행 시 출력되는 함수 역시 정규분포를 따르되, 평균과 분산이 입력으로 사용된 두 정규분포의 평균과 분산의 합으로 계산된다.
그래서, 합성곱을 수행하면 항상 출력값의 분산은 입력값의 두 정규분포 보다 커진다.
두 정규분포에 대한 합성곱이 수행되는 과정은 아래와 같이 영상에서 확인해볼 수 있다.
두 정규 분포의 곱(product)
두 번째로 이용될 상태 변화 연산은 두 정규 분포의 곱(product)이다.
두 정규 분포를 곱하면 어떤 결과가 얻어질까? 놀랍게도 정규 분포 두 개를 곱하면 결과는 정규 분포이다.
만약, 곱셈 결과로 얻어진 정규 분포를
\[\mathcal{N}_{new}(x; \mu_{new}, \sigma_{new}^2)\notag\]라고 하면 $\mu_{new}$와 $\sigma_{new}^2$은 다음과 같이 결정된다.
\[\mu_{new} = \frac{\mu_1\sigma_2^2 + \mu_2\sigma_1^2}{\sigma_1^2+\sigma_2^2}\] \[\sigma_{new}^2 = \frac{1}{1/\sigma_1^2+1/\sigma_2^2}=\frac{\sigma_1^2\sigma_2^2}{\sigma_1^2 + \sigma_2^2}\]그림으로 보면 다음과 같다.
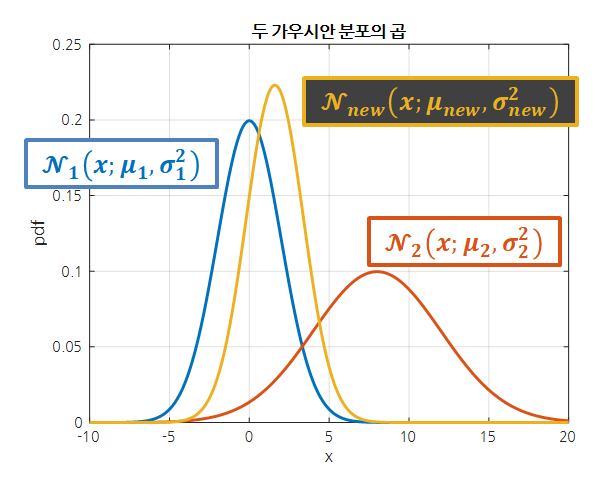
그림 3. 두 정규 분포의 곱(product)
$\mu_{new}$와 $\sigma_{new}^2$의 수식을 보아 알 수 있는 것은 다음과 같다.
먼저, $\mu_{new}$는 $\mu_1$과 $\mu_2$ 사이에 위치하며, 두 개의 정규 분포 중 분산이 작은 쪽에 더 가깝게 위치한다는 점이다.
또, $\sigma_{new}^2$ 의 식은 다음과 같이도 쓸 수 있는데,
\[\sigma_{new}^2=\sigma_1^2\frac{\sigma_2^2}{\sigma_1^2 + \sigma_2^2}=\sigma_2^2\frac{\sigma_1^2}{\sigma_1^2 + \sigma_2^2}\]이를 통해 확인할 수 있는 것은 새로운 $sigma_{new}^2$의 값은 $\sigma_1^2$ 혹은 $\sigma_2^2$ 보다 항상 작다는 것이다.
위치 추정과 이동
칼만 필터에서는 ‘상태’를 모두 정규 분포를 이용해서 표현한다고 하였다.
칼만 필터에서는 현재 위치와, 이동량을 모두 정규 분포를 이용해 표현할 수 있다.
이 때, 정규분포를 굳이 이용해 표현하면 얻을 수 있는 이점은 ‘불확실도’를 포함해 현재의 위치 혹은 이동량을 표현할 수 있다는 것이다.
가령, 위치를 측정하고자 하는 물체가 현재 $x=0$에 있을 가능성이 높다고 생각해보자.
여기서 서로 다른 두 개의 방법으로 위치를 측정한다고 했을 때, 불확실도가 다르다면 다음과 같이 정규분포의 분산을 달리하여 표현할 수 있는 것이다.
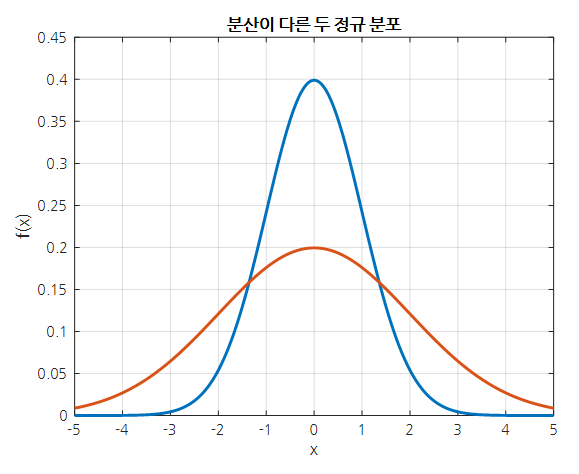
그림 4. 불확실도(분산)가 다른 두 정규분포의 비교
즉, 파란색으로 표시한 정규분포에 비해 주황색으로 표시한 정규분포는 $x=0$에 물체가 있을 것이라고 말하는 것에 대한 불확실도가 더 높다고 생각할 수 있다.
한편, 이동량 역시 정규 분포를 이용해 표현할 수 있다. 가령, 다음번 스텝에서 $x=4$만큼 오른쪽으로 이동하는 물체가 있다고 생각해보자.
하지만, 정확히 $x=4$ 만큼 이동할지에 대해서는 불확실도가 있기 때문에 다음과 같이 정규분포로 표현할 수 있는 것이다.
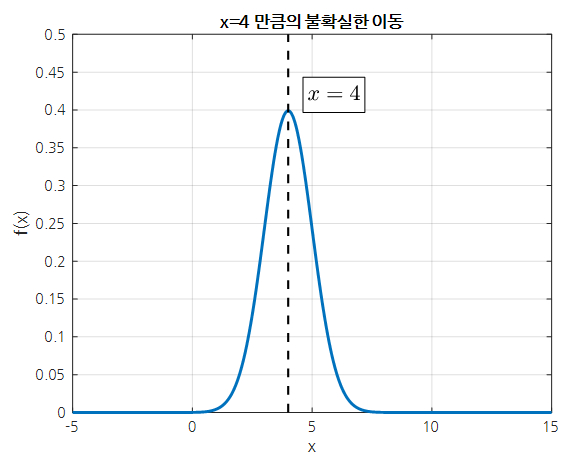
그림 5. x=4만큼 이동하지만, 불확실하게 이동하는 것을 정규분포로 표현할 수 있다.
그러면 $x=0$에 있던 물체를 매 스텝마다 $x=4$만큼 오른쪽으로 이동하게 된다면, 그 물체의 위치와 불확실도는 매 스텝마다 어떻게 변할까?
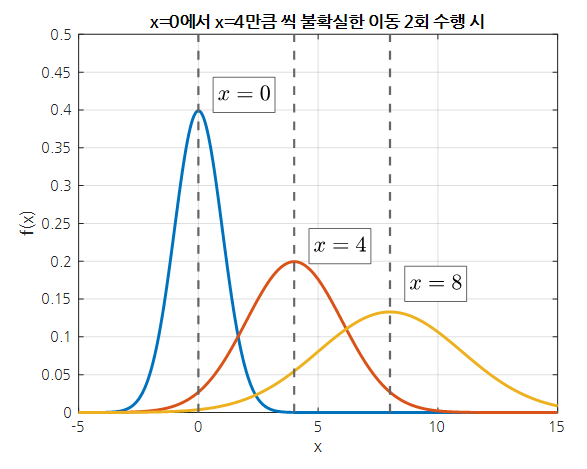
그림 6. x=0에 위치하던 물체를 x=4만큼 두 번 이동시켰을 때, 각 위치에서의 불확실도는 정규분포의 분산값으로 표현할 수 있다.
위 그림에서 물체가 이동할 때마다 불확실도가 커지는 것을 확인할 수 있다.
이것은 물체를 이동은 ‘원래 위치를 표현하던 정규분포’와 ‘이동에 관한 정규분포’의 두 식을 합성곱(convolution)처리해줌으로써 얻을 수 있는 것이기 때문이다.
정리하자면, 물체의 이동은 물체의 현재 위치와 물체의 이동에 관한 정규분포를 합성곱하여 표현할 수 있으며, 매 번 합성곱할 때 마다 위치에 관한 불확실도는 커지게 된다.
(이동에 관한 정규분포에 포함된 불확실도가 더 해져가기 때문이다.)
베이즈 정리: Update Rule
베이즈 정리는 조건부 확률에 관한 정리 중 하나로 다음과 같이 쓴다.
\[P(H|E) = \frac{P(E|H)P(H)}{P(E)}\]여기서 H는 Hypothesis, E는 Evidence라는 의미를 가진다.
베이즈 정리에서 중요한 점은 사전 확률과 사후 확률 간의 관계이다.
베이즈 정리는 확률에 대한 관점을 바꿔 이해해야 비로소 그 핵심을 이해할 수 있는데,
베이지안 주의에서 본 확률이란 ‘주장에 대한 신뢰도’이다. 베이즈 정리는 기존의 주장에 대한 신뢰도를 증거를 관찰함으로써 갱신하는 업데이트 룰에 대해 말하고 있다.
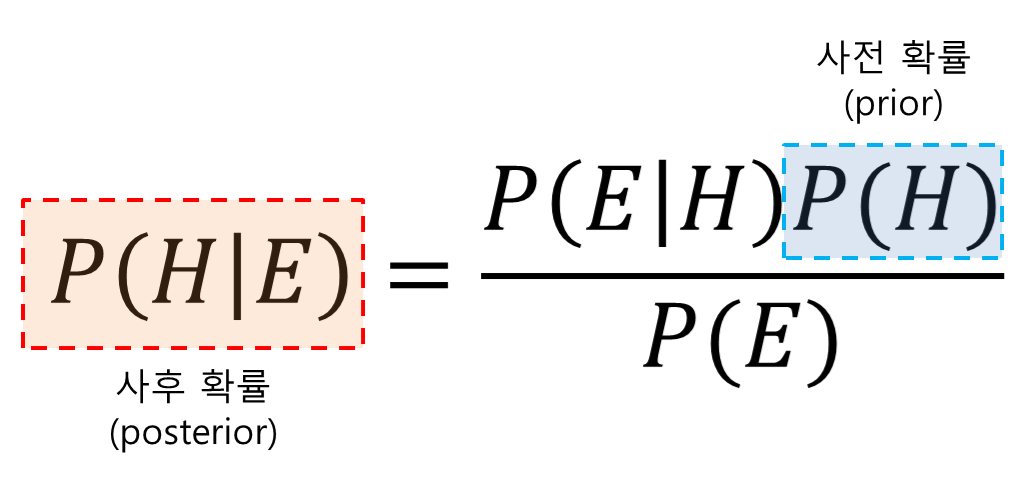
그림 7. 베이즈 정리에서 중요한 두 가지 확률 (사전확률, 사후확률)
베이즈 정리를 이해할 때의 또 다른 핵심 중 하나는 베이즈 정리의 식의 우변의 분모는 사후 확률 값을 ‘확률’로 만들어주는 정규화 과정에 불과하다는 것을 이해하는 것이다.
즉, 베이즈 정리가 아무리 복잡해보여도 $P(E)$는 단순히 확률값에 불과할 뿐이며, 이것은 정규화를 위한 과정일 뿐이라는 것이다.
따라서, 베이즈 정리의 식은 다음과 같이 써버릴 수도 있다.
\[P(H|E) = \frac{1}{Z}P(E|H)P(H)\]즉, 사후확률은 사전확률($P(H)$)과 likelihood($P(E|H)$)의 곱에 비례하는 값이라는 점이다.
매우 단순화시킨 칼만 필터의 작동 과정
칼만필터는 Predict와 Update라는 두 가지 과정을 거쳐가면서 작동해간다.
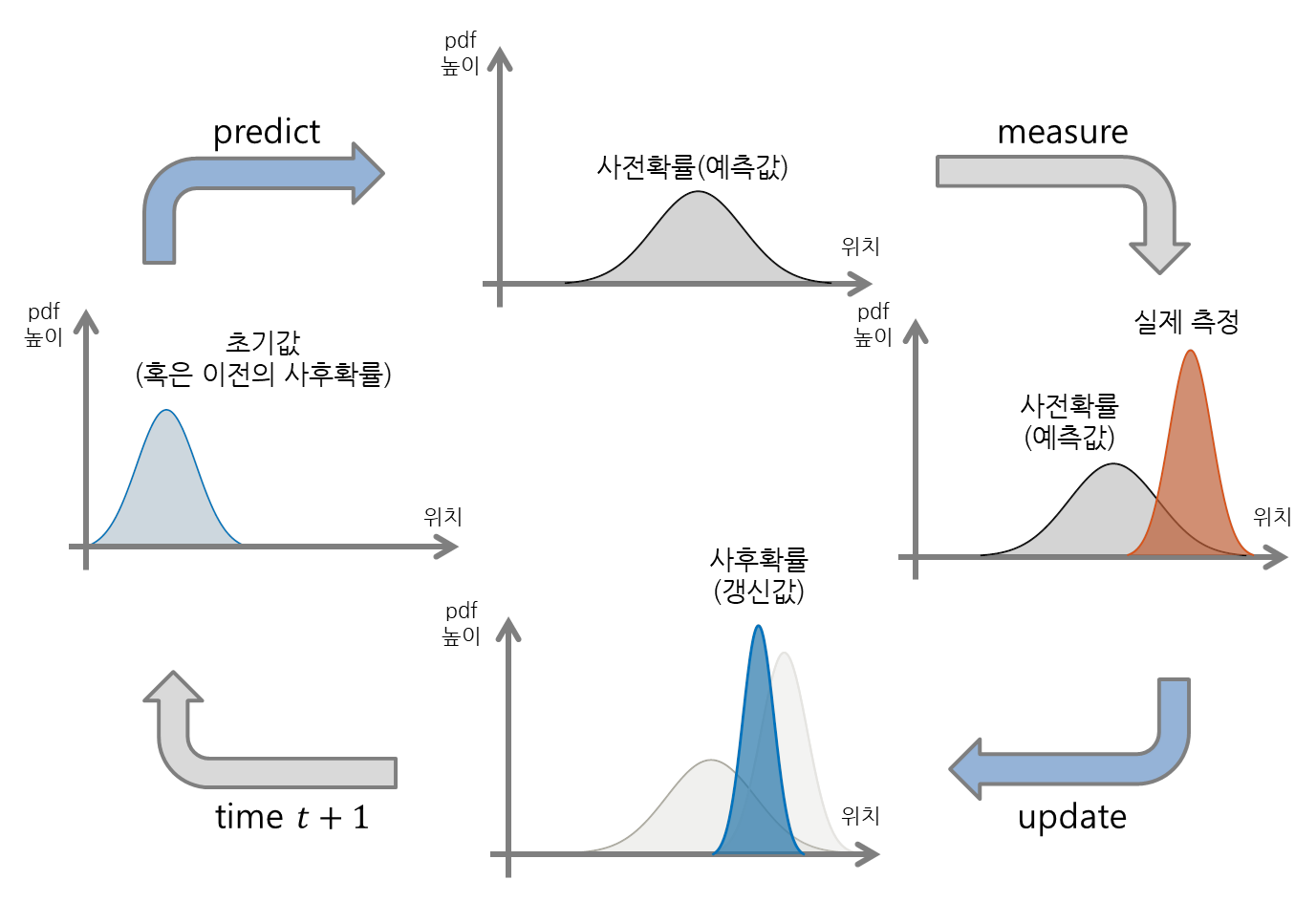
그림 8. 칼만 필터의 작동 단계는 Predict와 Update 두 가지로 구성되어 있다
Predict
Predict 단계에서는 현재 위치에서 다음 위치로 넘어가는 과정을 기술한 것이다.
다시 말해, 바로 이전 위치에서 현재 step으로의 이동을 수행하는 것이다. 여기서 현재 위치와 이동 모두 위치 추정과 이동 편에서 보았던 것 처럼 정규 분포를 이용해 표현되며, movement의 수행 과정은 합성곱(convolution)을 이용해 수행된다.
Update
Update 단계에서는 Predict를 통해 계산한 예측된 위치를 갱신해주는 과정을 거친다.
이 때 Bayes 정리와 정규 분포의 곱(product)이 이용되는데, Predict 단계에서 예측해보았던 확률 분포($P(H)$)와 실제 측정해본 위치에 관한 확률 분포($P(E|H)$)를 곱함으로써 갱신된 현재 위치에 관한 확률 분포($P(H|E)$)를 계산할 수 있게 된다.
이 때 정규 분포의 곱(product)를 이용해 갱신된 갱신된 현재 위치에 관한 확률 분포(사후 확률 분포)를 계산해내며,
정규분포의 곱 과정에서 보았듯이 곱해진 결과로써의 정규분포는 계속해서 분산이 줄어들기 때문에 일정한 법칙을 따라 predict 할 수 있다고 가정하면
사후확률의 분산값은 특정 값에서 수렴할 수 있게 된다. 다시 말해, measure만큼 정확한 위치에서 예측할 수 있게 된다.
단순한 칼만 필터의 작동 과정
그림 y.