시작하기에 앞서…
본 article에서는 나이브 베이즈 분류기의 작동 원리를 우선 파악하고, 그 수식을 얻게해준 배경 이론에 대해 추가적으로 이해해보고자 한다.
나이브 베이즈(naive Bayes) 분류기는 베이즈 정리를 이용해 만든 확률 분류기의 일종이다.
나이브 베이즈 분류기를 이해하기 위해서는 베이즈 정리의 수식보다는 베이즈 정리의 철학을 제대로 이해하는 것이 핵심적이다.
본 article을 더 잘 이해하기 위해선 아래의 내용에 대해 숙지하고 오는 것이 좋다.
- likelihood에 관한 이론: 최대우도법 소개 편
또한, 베이즈 정리에 대해 알고오면 더 도움이 될것이다.
- Bayes’ Rule에 대한 내용: 베이즈 정리의 의미 편
분류의 확률적 판단 근거를 찾아서
사전 지식을 이용한 분류: prior
확률적인 배경 지식을 가지고 특별한 추가 정보 없이 어떤 샘플을 분류하는 예시를 생각해보자.
가령 아무 사람이나 데리고 와서 어떤 정보도 없이 이 사람이 남자인지 여자인지 분류하라고 하면 어떻게 생각할 수 있을까?
세상에 절반은 남자고, 절반은 여자라고 생각한다면 50% 확률로 어림짐작 할 수 밖에 없다.
아마 랜덤하게 두 성별 중 하나를 얘기할 수 밖에 없을 것이다.
그런데, 가령 삼색이 고양이를 데리고 와서 고양이의 성별이 암컷인지 수컷인지 물어본다고 하자.
자세한 이유는 몰라도, 삼색이 고양이는 성염색체와 관련된 이유로 거의 대부분이 암컷이라고 알려져있다.
그렇다면, 삼색이 고양이를 봤다고 하면 높은 확률로 암컷이라고 생각하지 않을까?

그림 1. 성염색체와 관련된 이유로 삼색이 고양이는 99%가 암컷이라 알려져 있다.
이와 같이 test data sample에 대한 어떠한 정보(즉, feature)없이도 사전 지식만을 가지고 test data sample을
판별할 수도 있으며, 이러한 판별에 도움을 주는 확률값을 사전 확률(prior probability)이라고 한다.
참고로, 이러한 사전 확률은 실제 데이터에서는 training data에서 class간 비율을 가지고 미리 계산할 수 있다.
가령 100건의 training data에서 30:30:40의 비율로 class A, B, C가 주어져 있다면 각 클래스에 대한 사전확률 값은 0.3, 0.3, 0.4가 되는 것이다.
하지만, 실제로 어떤 데이터를 분류한다고 할 때에는 최소한의 판단 근거가 될만한 데이터를 제공하지 않을까?
특정 정보가 추가되는 경우: likelihood
키(즉, 특정 정보)에 따라 이 사람이 남자인지, 여자인지 판별하는 문제에 맞딱드렸다고 생각해보자.
우리는 주어진 training sample들을 통해 다음과 같이 남자와 여자의 키 분포가 다르다는 것을 알고 있다고 해보자.
(이러한 분포 모델링은 정규 분포를 가정하는 경우 training sample들의 평균과 분산을 계산함으로써 쉽게 구축할 수 있다.)
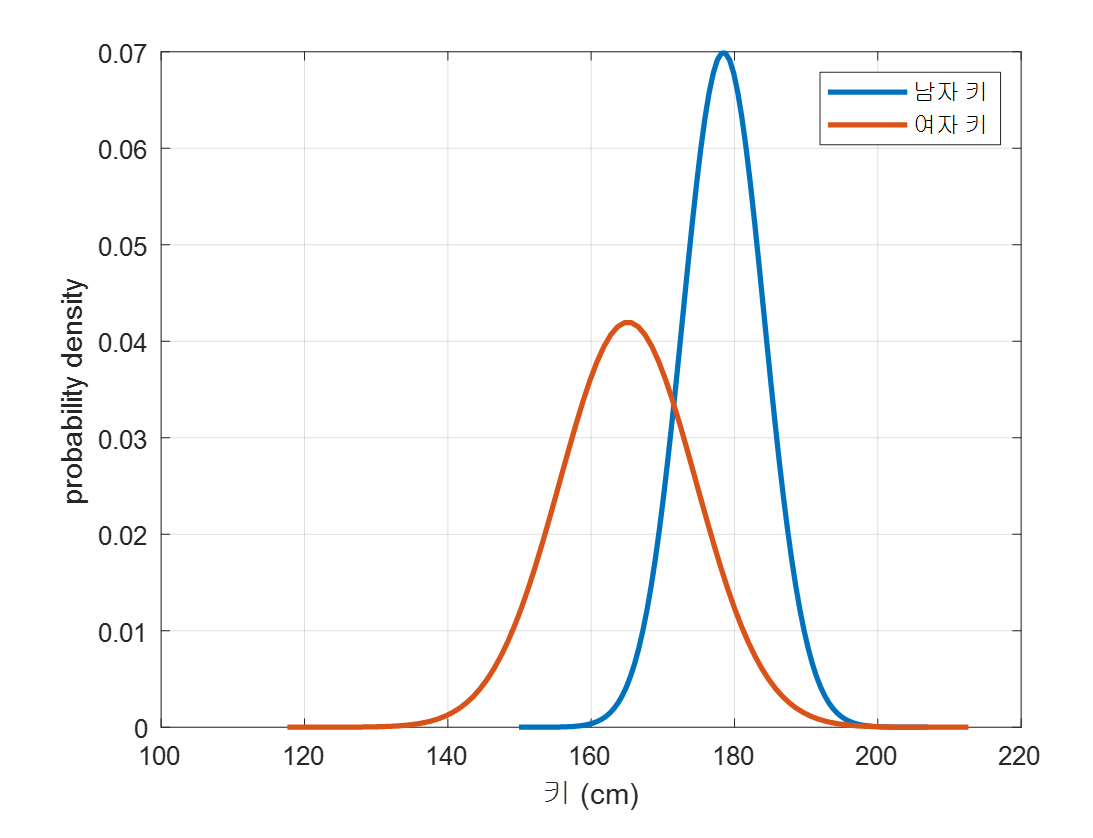
그림 2. training sample들을 통해 얻은 남자, 여자의 키 확률 분포
이 때, 우리가 분류하고자 하는 사람의 키가 가령 175cm라고 해보자. 그러면 175 cm에 대해 우리가 구축해놓은 확률밀도함수의 분포는 뭐라 말할까?
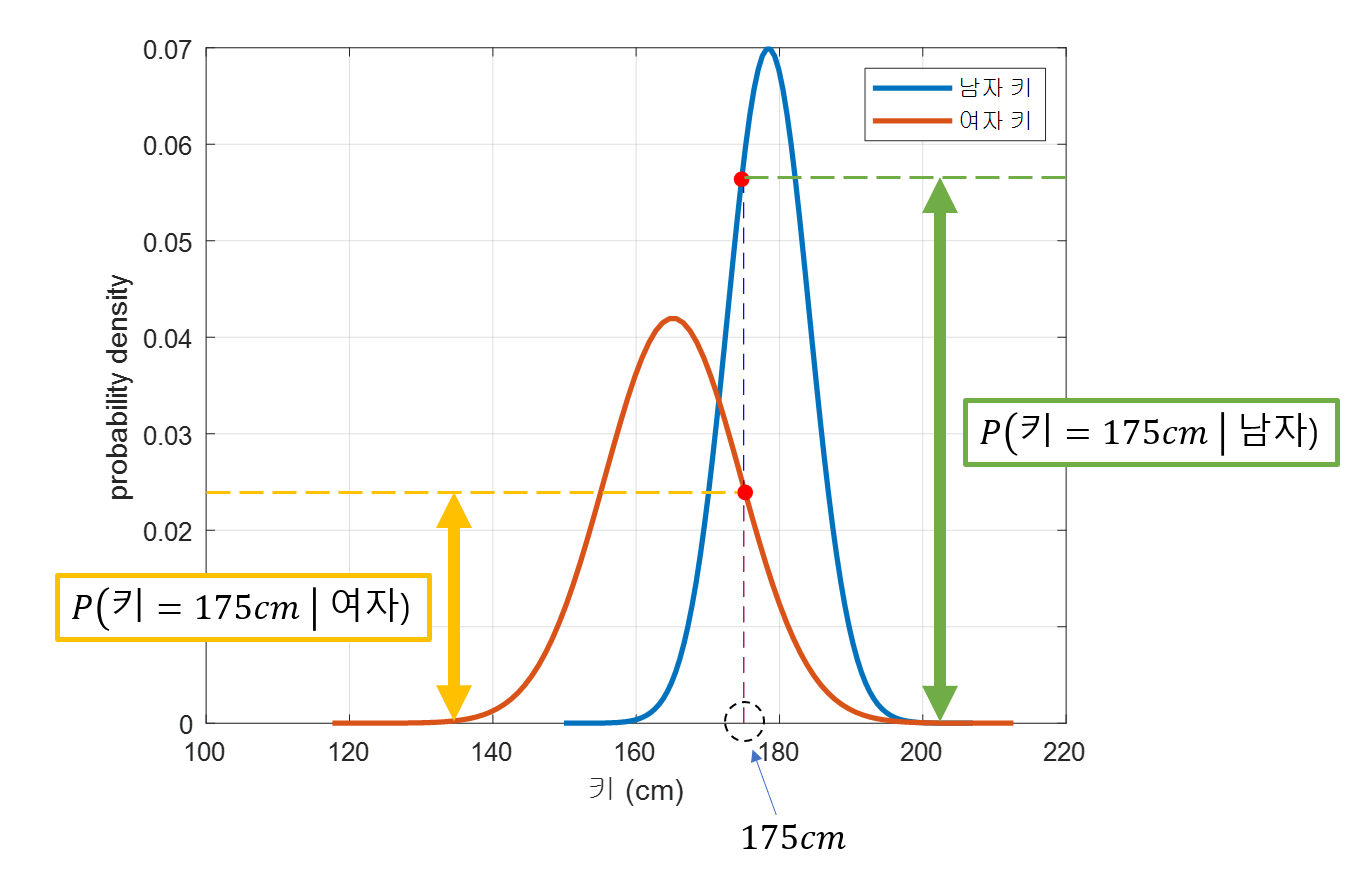
그림 3. 미리 구축해둔 남자, 여자의 키 확률 분포에 test data sample의 값을 대입시켜 본 경우
위의 그림 3을 보면 그 해답을 알 수 있다. 여자라고 생각하는 것 보다 남자라고 생각하는 것이 더 “가능성”이 커보인다는 것을 알 수 있다.
여기서 말하는 “가능성”이 바로 최대우도법 소개 편에서 언급한 “likelihood 기여도”이다.
이번 예시에서는 특징 정보가 하나밖에 없기 때문에 이 “likelihood 기여도”를 곧바로 likelihood라고 보자.
우리는 이 likelihood를 다음과 같이 생각할 수 있다.
남자라고 판단했을 때의 키가 175cm일 likelihood는 다음과 같이 쓸 수 있다.
\[P(키=175cm | 성별 = 남자)\]반면, 여자라고 판단했을 때 키가 175cm일 likelihood는 다음과 같이 쓸 수 있다.
\[P(키=175cm | 성별 = 여자)\]이번 예시에서는 식(1)과 식(2)의 두 likelihood의 값이 다음과 같다는 것 또한 알 수 있었다.
\[P(키=175cm | 성별 = 남자) > P(키=175cm | 성별 = 여자)\]우리는 식 (3)이 이 test data 사람의 성별이 남자라고 판단할 좋은 근거라는 것을 쉽게 이해할 수 있다.
그렇다면, 식(3)과 같은 likelihood 비교만으로 이 사람이 남자라고 판단할 충분한 근거가 될까?
그렇지는 않다.
왜냐하면 likelihood는 앞서 말했듯 ‘추가 정보’이기 때문이다. 즉, 우리가 기존에 알고있던 prior에 추가된 정보이므로
우리가 이 사람이 남자인지, 여자인지 판단하려면 기존의 배경 지식에다가 이번에 추가된 정보인 likelihood를 곱해주는 방식으로 “판단 근거”를 찾을 수 있다.
(즉, 사전지식을 완전히 무시할 수 없다.)
정리하자면, 남자라고 판단할 수 있는 판단 근거 $\text{prior} \times \text{likelihood}$는 다음과 같다.
\[P(성별 = 남자) \times P(키=175cm | 성별 = 남자)\]그리고, 여자라고 판단할 수 있는 근거에 관한 $\text{prior} \times \text{likelihood}$는 다음과 같다.
\[P(성별 = 여자) \times P(키=175cm | 성별 = 여자)\]우리는 이 두 $\text{prior} \times \text{likelihood}$를 비교함으로써 test data 사람의 성별을 비교할 수 있다.
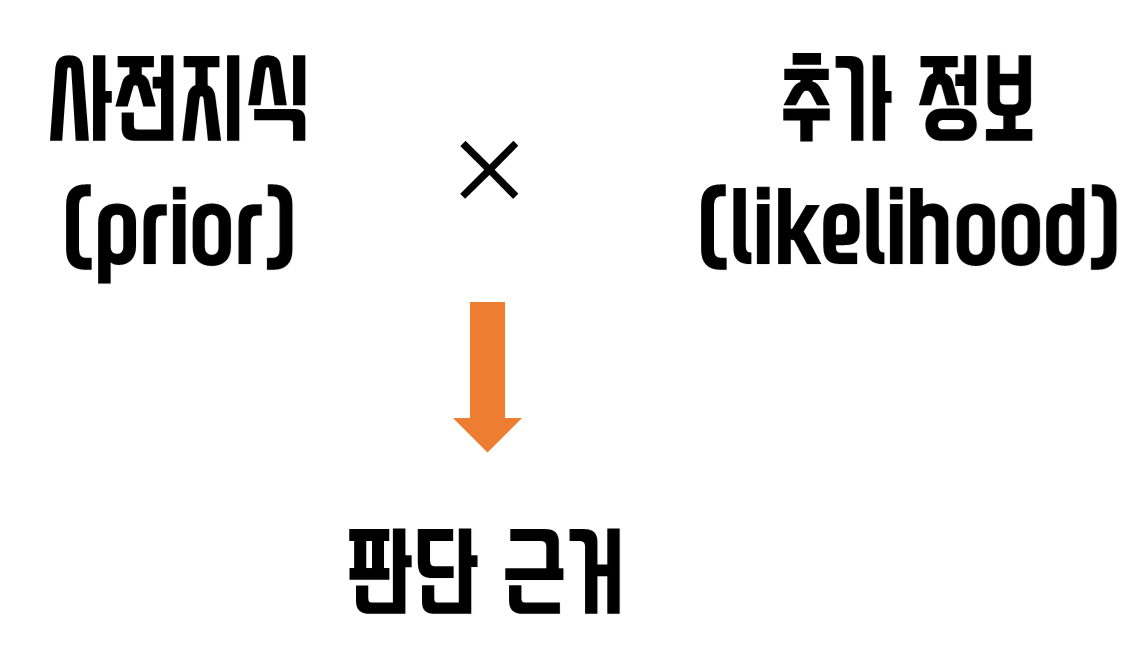
그림 4. 주어진 데이터를 판별(혹은 판단)하기 위해 사전 지식(prior)에 추가정보(likelihood)를 곱한 값을 판단근거로 삼을 수 있다.
정보가 더 추가된다면?
만약 정보가 더 추가 된다면 어떻게 하면 좋을까?
가령, 키 뿐만 아니라 몸무게에 관한 정보까지도 추가된다고 생각해보자.
그러면, 지금껏 사전 정보(prior)에 추가 정보(likelihood)를 곱해 추가해주었던 것 처럼 그 뒤에 계속 추가 정보를 덧붙이면 된다.
가령, 좀 전의 test data 사람의 몸무게가 80kg 이었다고 하면 판단 근거는 다음과 같이 업데이트 시킬 수 있다.
남자라고 판단한다고 할 때의 판단 근거는
\[P(성별 = 남자) \times P(키=175cm | 성별 = 남자)\times P(몸무게 = 80kg | 성별 = 남자)\]반면에 여자라고 판단한다고 할 때의 판단 근거는
\[P(성별 = 여자) \times P(키=175cm | 성별 = 여자)\times P(몸무게 = 80kg | 성별 = 여자)\]우리는 이 두 판단근거 수치를 비교함으로써 남자인지, 여자인지를 결정할 수 있는 것이다.
배경 이론 소개
앞서 설명한 전체 내용은 탄탄한 이론적 근거가 있다.
사실 베이즈 정리를 이용해 내용을 설명하자면 수식이 복잡해 보이는 것 같아 해당 내용은 뒷부분으로 옮겨보았다.
베이즈 정리에 관해서는 아래의 article을 참고해보도록 하자.
- Bayes’ Rule에 대한 내용: 베이즈 정리의 의미 편
이번 article의 이 꼭지에서는 베이즈 정리의 근본적인 의미보다는 수식적인 전개과정을 통해 위에서 설명한 ‘판단근거’가 도출되는 과정을 파악해볼 것이다.
베이즈 정리를 통한 ‘판단근거’ 도출
사실, 단도직입적으로 우리가 실제로 원하는 것은 이 데이터를 봤을 때 이 데이터가 어떤 클래스에 속하는지 판단하는 것이고,
그 판단 근거는 확률로부터 얻을 수 있다.
즉, 예를 들어 두 개의 클래스 $c_1, c_2$와 주어진 데이터 $x$에 대해서 다음과 같은 사후확률로부터 데이터의 클래스를 판단할 수 있다.
\[P(c_i | x)\text{ for }i=1, 2\]즉, 만약 $P(c_1 | x) > P(c_2 | x)$라면 이 샘플의 라벨은 $c_1$인 것이고, 그렇지 않으면 $c_2$인 것이다.
이것을 수식으로 표현하면 다음과 같을 것이다.
\[P(c_1 | x) >? P(c_2 | x)\]여기서 $A>?B$는 “A가 B보다 큰가?”로 이해하도록 하자.
위의 식(9)에 베이즈 정리를 적용하면 다음과 같다.
\[\frac{P(x | c_1)P(c_1)}{p(x)} >? \frac{P(x | c_2)P(c_2)}{p(x)}\]식 (10)을 자세히 보면 비교하고자 하는 두 확률값의 분모가 같다.
그러므로 $p(x)$가 어떤 값이든 간에 상관없이 클래스 판단에 대한 결과는 바뀌지 않으므로 무시할 수 있다.
그래서 식 (10)에서 분모는 제외한 값을 가지고도 클래스를 판단할 수 있게 된다.
\[P(x | c_1)P(c_1) >? P(x | c_2)P(c_2)\]데이터의 feature가 하나가 아닐 경우?
여러개의 feature를 가지고 class $c_i$ 을 판단하려면 수식이 약간 더 복잡해진다.
즉, 각 데이터 별로 클래스 $i=1,2,\cdots, k$에 대하여 $P(c_i | x)$ 대신에 $P(c_i | x_1, x_2, \cdots, x_n)$을 비교하는 것이다.
가령 클래스가 $c_1$, $c_2$ 두 가지만 있다고 했을 때 n개의 feature가 주어지는 경우 식(9)와 같은 수식을 쓰자면 다음과 같다.
\[P(c_1 | x_1, x_2, \cdots, x_n) >? P(c_2 | x_1, x_2, \cdots, x_n)\]여기서 $P(c_1 | x_1, x_2, \cdots, x_n)$만을 더 전개해보면 다음과 같다.
\[P(c_1 | x_1, x_2, \cdots, x_n) = P(c_1) P(x_1|c_1) P(x_2 | c_1, x_1) P(x_3 | c_1, x_1, x_2) \cdots P(x_n | c_1, x_1, x_2, \cdots x_{n-1})\]여기서 feature들은 모두 독립적으로 추출된다고 가정해보자.
(그래서 이런 과정을 거치는 분류기를 “naive” Bayes라고 부른다.)
그러면, 가령 $P(x_2 | c_1, x_1)$은 다음과 같이 쓸 수 있다.
\[P(x_2 | c_1, x_1) = P(x_2 | c_1)\]즉, $x_1$이 일어나든 말든 $x_2$의 확률에는 $x_1$의 발생여부가 조건으로써 영향을 받지 않는다는 것이다.
그래서 식 (13)을 다시 쓰면,
\[P(c_1 | x_1, x_2, \cdots, x_n) = P(c_1) P(x_1|c_1) P(x_2 | c_1) P(x_3 | c_1) \cdots P(x_n | c_1) \notag\] \[= P(c_1) \prod_{i=1}^{n}P(x_i | c_1)\]와 같이 되는 것이다. 이런 방식으로 식(6) 혹은 식(7)의 ‘판단근거’를 도출해낼 수 있게 되는 것이다.
한마디로 나이브 베이즈 분류기를 사용하게 되면 predicted class $\hat{y}$는 다음과 같다.
\[\hat{y} = argmax_{k\in \lbrace 1, 2, \cdots, k\rbrace}P(c_k)\prod_{i=1}^{n}P(x_i | c_k)\]